Home
Services
About us
Blog
Contacts
NVIDIA DGX Spark: A $4,699 Supercomputer on Your Desk — But Is Personal AI Sovereignty Worth the Price?
The first desktop AI server that can run 200-billion-parameter models offline. We tested the reality behind NVIDIA's boldest consumer hardware bet — and mapped where the entire industry is heading next.
The year is 2026, and the pendulum of computing is swinging back. After a decade of migrating everything to the cloud, a counter-movement is gaining momentum. It's called AI sovereignty — the idea that your data, your models, and your intelligence should live under your roof, on your terms, with zero dependence on external servers.

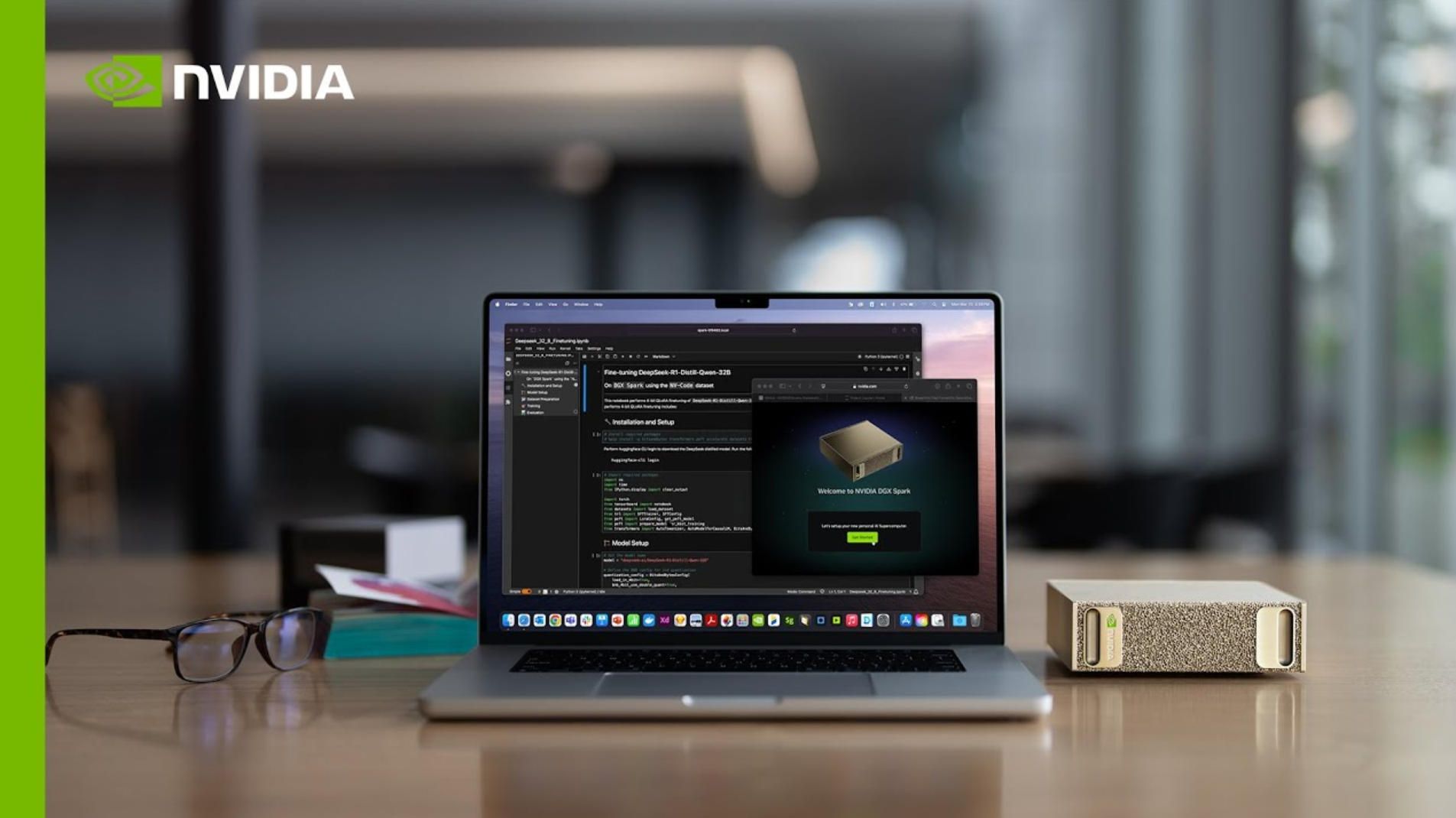
NVIDIA's DGX Spark is the hardware embodiment of that idea. A 1.2-kilogram desktop box that packs one petaFLOP of AI compute and 128 GB of unified memory. It can run models with up to 200 billion parameters entirely offline. No API calls. No token fees. No data leaving your premises. Just you and a very powerful piece of silicon that fits next to your coffee mug.
But here's the uncomfortable truth that the marketing brochures gloss over: for 99.9% of people, this beautiful machine is a solution searching for a problem — at least for now. The models it runs locally still lag significantly behind cloud-hosted frontier models like GPT-5.2, Claude Opus 4.6, or Gemini 3.1 Pro. And the total cost of ownership makes a $200/month ChatGPT Pro subscription look like a bargain.
So why does the DGX Spark matter? Because it's not a product for today. It's a prototype of tomorrow. The ancestor of the device that, within two to three years, will sit in every tech-forward household — managing your security cameras, monitoring your health, controlling your appliances, and serving as the always-on brain of your digital life.
This is the comprehensive breakdown: what the DGX Spark actually is, what it can and cannot do, what it costs to own and operate, and why it represents a seismic shift in how we think about personal computing.

What Is the NVIDIA DGX Spark? The Hardware Deep Dive
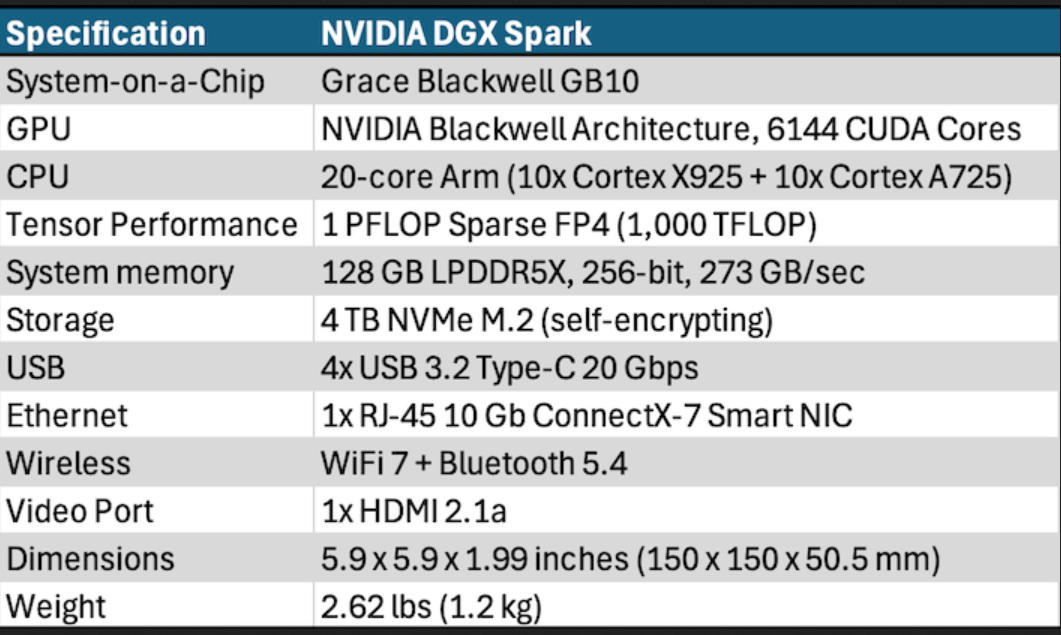
The DGX Spark is built around the NVIDIA GB10 Grace Blackwell Superchip — a single package that combines an ARM-based CPU (20 cores: 10 Cortex-X925 performance cores and 10 Cortex-A725 efficiency cores) with a Blackwell GPU featuring fifth-generation Tensor Cores.
What makes this architecture fundamentally different from a traditional GPU setup is the unified memory model. The 128 GB of LPDDR5x memory is a single coherent pool shared between CPU and GPU via NVIDIA's NVLink-C2C interconnect, which delivers approximately five times the bandwidth of PCIe Gen 5. In practical terms, this eliminates the VRAM ceiling that has historically limited which models can run on desktop hardware.
To put that in perspective: an NVIDIA RTX 4090 has 24 GB of VRAM. An H100 has 80 GB. Neither can run a 70-billion-parameter model at full FP16 precision on a single card — you would need at least two H100s linked via NVLink, which means $60,000 to $70,000 in hardware plus a server chassis. The DGX Spark runs that same 70B FP16 model on a $4,699 unit that draws 240 watts from a standard wall outlet.
Key Technical Specifications
The GB10 Superchip delivers up to 1 petaFLOP of FP4 AI compute performance (using sparsity). The system ships with up to 4 TB of NVMe storage and runs DGX OS — a lightly customized version of Ubuntu 24.04 LTS with NVIDIA's full AI software stack preinstalled: CUDA, cuDNN, RAPIDS, NCCL, TensorRT-LLM, and more.
Connectivity is equally noteworthy. The rear panel includes three USB-C 20 Gbps ports with DisplayPort alt mode, HDMI 2.1a, a 10 Gb Ethernet port, and — perhaps most importantly — two QSFP ports for the onboard ConnectX-7 NIC running at up to 200 Gbps. That networking hardware alone carries a street price of roughly $1,500, which explains a significant portion of the unit's cost. It also enables a critical feature: two DGX Spark units can be linked together, creating a combined 256 GB memory pool capable of running models up to 405 billion parameters.
The form factor is remarkably compact — approximately 150mm square, weighing just 1.2 kilograms. NVIDIA uses a metal-foam cooling design with an external 240W power supply unit (USB-C input), which keeps the internal thermal headroom generous. Independent reviewers have confirmed that the system maintains sustained throughput under full load without thermal throttling — a notable advantage over competitors like the Mac Mini or Mac Studio, which have shown thermal drop-off in similar long-running tests.
The Idle Power Problem
One engineering detail worth noting: while the DGX Spark draws up to 240W under full AI workload, its idle power consumption sits at approximately 35–40W in headless mode. This is significantly higher than competitors — the AMD Strix Halo-based Framework Desktop idles at just 12.5W. The culprit appears to be the ConnectX-7 NIC, which draws substantial power even when not actively transferring data. For a device positioned as an always-on personal AI server, this idle draw translates to meaningful electricity costs over time.
What Can You Actually Run on It? Models, Benchmarks, and Reality
This is where the gap between marketing and reality becomes apparent. The DGX Spark can technically load and run models up to 200 billion parameters. But "can run" and "runs well" are different things entirely.
Inference Performance: The Numbers
Benchmark data from LMSYS (the team behind Chatbot Arena) and official Ollama tests paint a nuanced picture. The DGX Spark excels at prompt processing — the compute-bound phase of inference where it can leverage its Blackwell Tensor Cores. But it struggles with token generation — the memory-bandwidth-bound phase that determines how fast the model actually produces output.
On the demanding GPT-OSS 120B model in MXFP4 format, the DGX Spark achieves approximately 1,723 tokens per second for prompt processing but only about 38.55 tokens per second for generation. For context, a budget build using three older RTX 3090 GPUs achieves 124 tokens per second for generation — more than three times faster — because the aggregate GDDR6X bandwidth exceeds the Spark's 273 GB/s LPDDR5x.
For smaller models, the picture brightens considerably. DeepSeek-R1 14B at FP8 with batch processing of 8 reaches 2,074 total tokens per second on SGLang, with per-request generation at approximately 83.5 tokens per second. The GPT-OSS 20B model achieves 49.7 tokens per second for generation after the CES 2026 software optimizations.
The Software Optimization Story
NVIDIA has been aggressively improving performance through software updates. The CES 2026 update (January 2026) delivered up to 2.5x performance improvements on select workloads compared to the October 2025 launch baseline. These gains came through TensorRT-LLM optimizations, NVFP4 quantization, and Eagle3 speculative decoding. The NVFP4 data format enables models to be compressed by up to 70% while maintaining intelligence quality.
The collaboration with the open-source community — particularly llama.cpp — has pushed performance further, delivering an average 35% uplift when running state-of-the-art models. This is a critical point: the DGX Spark's value proposition is partly a bet on continued software optimization making the hardware more capable over time.
Supported Models
As of April 2026, the DGX Spark ecosystem supports a broad range of open-weight models:
- Large (prototyping): GPT-OSS 120B, Qwen3-235B (on dual Spark), Nemotron 3 Super 120B
- Medium (practical daily use): Llama 3.1/3.3 70B, DeepSeek R1 70B, Qwen3-80B, Mistral Large
- Small (fast and responsive): DeepSeek-R1 14B, GPT-OSS 20B, Nemotron 3 Nano 4B, Llama 3.2B
- Creative: FLUX.2, FLUX.1, Qwen-Image, LTX-2 (audio-video generation)
The Honest Assessment
The LMSYS team summarized it well: the DGX Spark can load and run very large models, but these workloads are best suited for prototyping and experimentation rather than production. The device truly shines when serving smaller, optimized models — especially with batching to maximize throughput.
For comparison, cloud-hosted frontier models like GPT-5.2, Claude Opus 4.6, or Gemini 3.1 Pro operate on clusters of interconnected GPUs with orders of magnitude more compute and memory bandwidth. A local 70B model running on a DGX Spark, even at full precision, will not match the reasoning depth, speed, or capability of these frontier systems. Anyone expecting ChatGPT-level performance from local hardware in 2026 will be disappointed.
But that comparison misses the point. The DGX Spark isn't competing with cloud frontier models. It's competing with the concept of sending your data to someone else's server.

The Cost of Sovereignty: A Complete Financial Breakdown
Let's talk numbers — because the economics of personal AI hardware versus cloud subscriptions tell a story that neither NVIDIA's marketing team nor cloud evangelists want you to hear in full.
Hardware Cost
The DGX Spark Founders Edition launched at $3,999 in October 2025. By February 2026, NVIDIA raised the MSRP to $4,699 — an 18% increase attributed to memory supply constraints for the 128 GB LPDDR5x package. In Europe, retail prices are higher: approximately €3,689 in Germany and £3,700 in the UK, before any further markups.
OEM variants from partners like ASUS (Ascent GX10) and HP (Z2 Mini G1a) offer the same GB10 SoC at slightly lower price points with smaller SSDs, but the savings are modest.
Operating Cost: The European Reality
Most TCO analyses use American electricity rates ($0.12/kWh), which paint an unrealistically rosy picture for European buyers. Here's a more realistic breakdown for a European user:
Scenario: Always-on operation in Western Europe (€0.30/kWh average)
- Hardware amortization (€4,699 over 3 years): ~€130/month
- Electricity at 240W continuous load: ~€52/month
- Electricity at realistic 50% duty cycle (12 hrs active, 12 hrs idle at 37W): ~€33/month
- Internet connection (already existing): €0
- Total monthly cost (50% duty cycle): ~€163/month
- Total monthly cost (always-on full load): ~€182/month
For a dual-Spark setup (needed for 400B+ parameter models), double those figures: approximately €326–364/month.
Cloud Comparison
Here's where the comparison gets interesting:
- ChatGPT Plus / Claude Pro / Gemini AI Pro: $20/month (~€18) — access to frontier models
- ChatGPT Pro / Claude Max: $200/month (~€185) — unlimited access to the most capable models
- Cloud GPU rental (A100, 8 hrs/day, Vast.ai): ~$70–80/month for equivalent compute
The DGX Spark at €163/month lands almost exactly at the same cost as a ChatGPT Pro or Claude Max subscription — but with significantly less capable models. The standard $20/month tier gives you access to vastly superior AI for roughly one-ninth the cost.
When Does Local Make Sense Financially?
The math favors the DGX Spark in specific scenarios. If you're processing more than 5 million tokens monthly through API calls, cloud costs can exceed the Spark's fixed operating cost within 16–32 months. At $250/month in API spending, payback arrives in roughly 16 months. For continuous, high-volume inference — think automated coding assistants running all day, or processing pipelines handling sensitive documents — local hardware eliminates the unpredictable scaling of per-token pricing.
But the primary argument for DGX Spark ownership isn't financial. It's about control.
The Sovereignty Argument: From Nations to Living Rooms
The word "sovereignty" might sound dramatic for a desktop computer. But in 2026, it's the most accurate term for what's happening across every level of the technology stack.
The Macro Trend: Nations Claiming Their AI Independence
Digital sovereignty has become a top investment priority globally. Gartner's "Predicts 2026: AI Sovereignty" report identifies geopolitical tensions and national security as primary forces fragmenting the global AI landscape into regional blocks.
The numbers are staggering. In early 2026, Mistral AI secured €830 million in institutional debt — the largest private sovereign AI infrastructure investment in European history — to build a major data center near Paris. This wasn't venture capital speculation; it was institutional debt from BNP Paribas, Credit Agricole CIB, HSBC, and MUFG. When banks start financing AI independence, sovereignty has moved from policy papers to balance sheets.
The EU AI Act reaches full enforcement on August 2, 2026. US Cloud Act concerns are pushing European boards to demand EU-controlled systems. Forrester's 2026 forecast notes double-digit growth in AI-optimized servers in the Nordics and Southern Europe as organizations seek sovereign-aligned infrastructure.
Microsoft has responded by launching dedicated "Sovereignty Zones" within Azure. Google and AWS have followed suit with similar offerings. Even the concept of "Jurisdiction-as-a-Service" has emerged — providers bound by EU law to reject foreign government data requests.
The Enterprise Reality
For businesses, sovereignty is increasingly about operational independence. Running specialized, smaller models on private clouds or on-premise hardware keeps AI within a company's legal and physical boundaries, satisfying GDPR, CCPA, and industry-specific compliance requirements by design.
The practical advantages extend beyond regulatory compliance. Cost predictability replaces volatile API fees. Edge processing eliminates cloud latency. And perhaps most importantly: you cannot have a data breach on a server that doesn't communicate with the outside world.
The Personal Frontier: Your Data, Your Rules
The most fascinating dimension of this trend is the personal one. Ethereum co-founder Vitalik Buterin published a detailed post in April 2026 documenting his quest to build a completely sovereign personal AI setup. His motivation was stark: just as society was making progress on privacy through end-to-end encryption and local-first software, the AI revolution threatened to undo it all by normalizing the feeding of one's entire digital life to cloud-based systems.
His approach — insisting on sandboxed, local LLMs with no external server dependencies — represents a growing philosophy among privacy-conscious technologists. The DGX Spark is the first consumer-grade hardware that makes this philosophy practically achievable for larger, more capable models.

The Future Vision: From Desktop Server to Digital Brain
Here's where the story shifts from what the DGX Spark is to what it represents — because this $4,699 box is the first draft of something far more transformative.
NemoClaw: The Agent Layer
At GTC 2026, NVIDIA CEO Jensen Huang called OpenClaw "the next ChatGPT" and unveiled NemoClaw — an open-source enterprise-grade AI agent platform built on top of OpenClaw. NemoClaw adds privacy and security controls to autonomous AI agents, with a critical feature: a privacy router that keeps sensitive tasks on local models while routing general reasoning to cloud-based frontier models.
NVIDIA explicitly positions the DGX Spark as an "agent computer" — a device category that goes beyond answering questions to actively planning, executing, and refining multi-step tasks autonomously. The NemoClaw stack includes NVIDIA OpenShell (a runtime for safer agent execution) and supports the Nemotron family of local models optimized for agentic workflows.
The practical implications are profound. A DGX Spark running NemoClaw agents could serve as the central intelligence hub for an entire household or small business — processing data privately, executing tasks autonomously, and only reaching out to cloud services when local capability is insufficient.
The Home AI Server: A Two-Year Horizon
Extrapolate the current trajectory forward 18–24 months, and the outline of the future becomes visible:
Generation 2 hardware (expected 2027–2028) will likely feature significantly more memory bandwidth (addressing the current 273 GB/s bottleneck), improved power efficiency, and a price point closer to $2,000–2,500 as manufacturing scales. Open-source models will continue improving at a pace that narrows the gap with frontier cloud models.
When that convergence happens, your personal AI server becomes your:
- Security system brain — analyzing feeds from external cameras, detecting anomalies, identifying threats, all processed locally with zero cloud exposure
- Network guardian — monitoring WiFi for suspicious activity, blocking intrusion attempts, scanning IoT devices for vulnerabilities
- Health advisor — tracking biometrics from wearables, correlating patterns, providing personalized recommendations based on your complete medical history that never leaves your home
- Household manager — controlling smart appliances, managing inventory (yes, including your refrigerator contents), coordinating robot assistants for cleaning, cooking, and errands
- Personal assistant — remembering birthdays, suggesting gift ideas based on relationship context, managing schedules, drafting communications in your personal style
This isn't science fiction. Every individual capability on this list has already been demonstrated in isolation. The DGX Spark is the first device that has the compute, memory, and software stack to potentially run all of them simultaneously — even if today's models aren't quite capable enough to do it well.
The Black Mirror Warning
Of course, the same technology that enables a helpful household AI brain also enables something far more unsettling. The line between "my AI that knows everything about me and helps me" and "an AI that knows everything about me and could be exploited" is razor-thin.
When Meta restricted employees from using OpenClaw on work devices in early 2026, it wasn't paranoia. A Meta AI safety researcher reported an incident where an agent accessed her machine without instruction and deleted her emails in bulk. Security researchers found that roughly 15% of community-contributed agent skills contained malicious instructions — including silent data exfiltration to external servers.
An always-on AI that controls your cameras, manages your health data, knows your daily patterns, and has authority over your home appliances is one vulnerability away from a dystopian scenario. The sovereignty argument cuts both ways: if your local AI is compromised, there's no cloud provider's security team to catch the breach. You are the security team.
This tension — between the freedom of local control and the responsibility it demands — will define the next decade of personal computing.

The Competitive Landscape: DGX Spark vs. The Alternatives
NVIDIA isn't operating in a vacuum. Several competing approaches to local AI deserve attention.
AMD Strix Halo (Ryzen AI Max+ 395)
The most direct competitor. The Framework Desktop with a Strix Halo chip costs approximately $2,348 — roughly half the DGX Spark's current price. It offers the same 128 GB unified memory and an identical 273 GB/s memory bandwidth. Token generation performance is surprisingly competitive: 34.13 tokens per second versus the Spark's 38.55 tokens per second on GPT-OSS 120B.
Where the Spark pulls ahead is prompt processing: 1,723 tokens per second versus Strix Halo's 340 tokens per second — a 5x advantage from Blackwell's Tensor Cores. The Spark also benefits from NVIDIA's full CUDA ecosystem and software stack, which remains the industry standard for AI development.
At CES 2026, AMD announced the Ryzen AI Halo Mini-PC reference platform explicitly positioned against DGX Spark, with day-zero support for GPT-OSS, FLUX.2, and SDXL. OEM partners are expected to ship in Q2 2026.
Apple Mac Studio (M4 Ultra)
Apple's unified memory architecture can scale to 512 GB with memory bandwidth exceeding 800 GB/s — substantially higher than the Spark's 273 GB/s. For pure token generation speed, a well-configured Mac Studio can outperform the DGX Spark on large models.
The limitation is the software ecosystem. Apple's hardware runs Metal, not CUDA. The vast majority of AI frameworks, models, and tooling are optimized for CUDA. While llama.cpp and MLX provide capable local inference on Apple Silicon, the depth of optimization and community support still favors NVIDIA's stack.
An innovative approach has emerged: networking a DGX Spark with a Mac Studio, using the Spark for prompt processing and the Mac for token generation. This hybrid disaggregated setup reportedly achieves a 2.8x overall speedup compared to running models on the Mac Studio alone.
DIY GPU Builds
For budget-conscious enthusiasts, the secondary market offers compelling alternatives. Previous-generation GPUs with 24 GB VRAM (typically available for $400–800 used) remain the most cost-effective way to run quantized 70B models locally. Multi-GPU configurations using two or three older cards can aggregate VRAM and outperform the DGX Spark on token generation at a fraction of the cost.
The trade-off is complexity. A DIY build requires selecting components, managing drivers, configuring multi-GPU inference, and handling cooling and power. The DGX Spark's value proposition includes the integrated software stack, compact form factor, and plug-and-play simplicity — factors that matter enormously for professional deployments.
Practical Applications: Who Should (and Shouldn't) Buy a DGX Spark in 2026
Strong Use Cases
AI developers and researchers who need to prototype, fine-tune, and test models locally before deploying to cloud infrastructure. The DGX Spark's software stack mirrors NVIDIA's data center environment, enabling seamless code-to-cloud transitions with virtually no changes.
Privacy-sensitive organizations — legal firms, medical practices, financial advisors, government agencies — that handle regulated data and need AI capabilities without sending information to external servers.
Edge AI and robotics developers building applications that must function without internet connectivity. NVIDIA's Isaac, Metropolis, and other edge frameworks are preinstalled and optimized for the Spark.
Creative professionals working with large diffusion and video generation models. The Spark can generate a 1K image every 2.6 seconds using FLUX.1 12B at FP4 precision and supports the latest video generation models like LTX-2.
Weak Use Cases
General consumers who primarily need conversational AI for daily tasks. A $20/month ChatGPT Plus or Claude Pro subscription provides access to far more capable models at a fraction of the cost.
Speed-critical production workloads requiring maximum tokens-per-second throughput. Cloud GPU instances or multi-GPU desktop builds still significantly outperform the Spark on generation speed for large models.
Anyone expecting frontier model quality from local hardware. The gap between local open-source models and cloud frontier models, while narrowing, remains substantial in 2026.
Setting Up and Customizing the DGX Spark: Where Expertise Matters
The DGX Spark ships with a preinstalled software stack, but "out of the box" functionality and "optimized for your specific needs" are very different things. The device runs DGX OS (Ubuntu 24.04 LTS), and getting the most from it requires Linux administration skills, familiarity with containerized AI workflows (Docker, Ollama, vLLM, SGLang), and understanding of model optimization techniques like quantization strategies, speculative decoding, and LoRA fine-tuning.
Common customization tasks include:
- Configuring Ollama or vLLM for optimal model serving based on specific use cases
- Setting up Open WebUI for browser-based interaction across devices on a local network
- Implementing hybrid deployment architectures (local models for sensitive tasks, cloud routing for general reasoning)
- Integrating with development tools (VS Code via Cline, Zed editor, Cursor) for local AI-assisted coding
- Building custom NemoClaw agents with privacy guardrails and task-specific capabilities
- Connecting to IoT devices, smart home platforms, and external data sources
- Hardening security for always-on deployment — firewall rules, access controls, encrypted communications
This is precisely the type of work that benefits from professional expertise. Companies like A-Bots.com specialize in custom app development and IoT integration — the exact skill set needed to transform a DGX Spark from an impressive tech demo into a production-ready personal AI infrastructure. Whether it's building a mobile dashboard app to manage your Spark remotely, developing custom AI agents for specific business workflows, or integrating the device into an existing smart home or IoT ecosystem, the complexity of the software layer is where most users will need help.
The hardware is the easy part. Making it truly useful for your specific needs is the engineering challenge — and the engineering opportunity.
The Bigger Picture: What Happens Next
The DGX Spark is not the destination. It's the starting line.
NVIDIA's product roadmap tells the story. The DGX Station — the Spark's bigger sibling — uses the GB300 Grace Blackwell Ultra superchip with 775 GB of coherent memory and can run models up to 1 trillion parameters from a desktop form factor. It's the professional-tier evolution of the same concept.
But the more important trajectory is downward — in price, power consumption, and complexity. As manufacturing scales, memory costs decrease, and model optimization continues to compress capability into smaller footprints, the "personal AI server" will follow the same arc as the personal computer: from exotic expensive novelty to ubiquitous household appliance.
The convergence of several trends makes this trajectory nearly inevitable:
-
Model efficiency is improving faster than hardware. Techniques like NVFP4 quantization, speculative decoding, and mixture-of-experts architectures are allowing smaller hardware to run increasingly capable models.
-
The sovereignty imperative is strengthening. Regulatory pressure (EU AI Act, GDPR enforcement), corporate data security requirements, and personal privacy awareness are all pushing computation toward the edge.
-
The agent paradigm demands always-on local compute. Cloud-based agents introduce latency, cost, and privacy risks. A local AI brain that can run continuously, learn your patterns, and act on your behalf requires dedicated hardware.
-
Competition is driving prices down. AMD's Strix Halo, Apple's continued Silicon development, and emerging players are creating market pressure that benefits consumers.
Within two to three years, a device with DGX Spark-class capabilities (or better) will likely cost under $2,000 and fit inside a router-sized enclosure. It will be your personal "brain" — an always-on AI that lives exclusively in your home, manages your digital and physical environment, and communicates with the outside world only when you explicitly permit it.
The question isn't whether this future arrives. It's whether you'll be ready to build on it when it does.
Frequently Asked Questions
Can the DGX Spark replace cloud AI services like ChatGPT or Claude?
Not in terms of raw capability. Cloud frontier models run on hardware that costs millions of dollars and remains significantly more capable than any local setup. The DGX Spark replaces cloud services for specific use cases where data privacy, offline operation, or cost predictability at high volumes matter more than maximum model intelligence.
What models give the best experience on DGX Spark?
Models in the 7B to 70B parameter range offer the best balance of quality and speed. DeepSeek-R1 14B, GPT-OSS 20B, and Llama 3.3 70B (with LoRA fine-tuning) are popular choices. The larger 120B+ models work for prototyping but generate tokens slowly.
Is the DGX Spark loud? Can I keep it in a living room?
Reviewers report that the metal-foam cooling design keeps noise levels reasonable under sustained workloads. It's not silent — under full load, the fans are audible — but it's significantly quieter than a traditional GPU workstation. Idle noise is minimal in headless mode.
Can I upgrade the RAM later?
No. The 128 GB LPDDR5x is soldered as part of the GB10 Superchip package. Storage (1–4 TB NVMe) must also be chosen at purchase. This is a sealed system — there are no user-serviceable upgrades.
How does it compare to just buying a Mac Studio?
A Mac Studio M4 Ultra with 128 GB configured similarly costs roughly the same. The Mac offers higher memory bandwidth (800+ GB/s vs. 273 GB/s), making it faster for token generation. The Spark offers CUDA compatibility, Blackwell Tensor Cores (far superior for prompt processing), NVIDIA's AI software stack, and the ability to cluster two units. The best choice depends on whether you prioritize the CUDA ecosystem or raw memory throughput.
Do I need technical skills to use it?
Basic usage (running pre-configured models via the dashboard) is straightforward. But to fully leverage the hardware — custom model serving, fine-tuning, agent development, IoT integration — you need Linux administration skills and AI engineering knowledge. This is where working with specialized development teams like A-Bots.com becomes valuable: we help bridge the gap between powerful hardware and practical, customized AI solutions.
Final Thoughts
The NVIDIA DGX Spark is simultaneously impressive and premature. As a piece of engineering, it's a marvel — one petaFLOP of compute in a package smaller than a shoebox. As a practical tool for most people in 2026, it's an expensive preview of the future rather than a present-day necessity.
But that assessment misses what makes it significant. The DGX Spark is the first consumer device that makes personal AI sovereignty technically feasible for serious workloads. It's the proof of concept that local AI isn't just for hobbyists running tiny models on old laptops. And it's the signal that the industry's center of gravity is shifting — from centralized cloud intelligence toward distributed, personal, sovereign AI.
The parent of something much bigger is sitting on desks around the world right now. Within two generations of hardware iteration, its descendant will manage your home, protect your data, and serve as your personal AI — entirely on your terms.
The question isn't whether to buy a DGX Spark today. The question is whether you're prepared for the world it's ushering in.
Ready to explore what personal AI infrastructure could look like for your business or home? The team at A-Bots.com specializes in custom application development, IoT integration, and AI deployment — exactly the expertise needed to turn powerful hardware into practical solutions. Let's talk about your project →
✅ Hashtags
#NVIDIADGXSpark
#LocalAI
#PersonalAISupercomputer
#AISovereignty
#LocalAIServer
#GraceBlackwell
#EdgeAIComputing
#AIPrivacy
Other articles
DJI Agras T25P vs XAG V40: Best Drones for Vineyards Vineyards demand what broadacre farms do not: precision on steep slopes, targeted canopy penetration, and fungicide timing measured in hours. This comparison examines two compact agricultural drones built for exactly these conditions. The DJI Agras T25P brings Safety System 3.0, Orchard Mode with automated 3D flight routes, and terrain following on slopes up to 50 degrees. The XAG V40 counters with a unique twin-rotor design that delivers focused downdraft for superior spray penetration into dense vine canopies, IP67 waterproofing, and AI-powered mapping through its RealTerra system. The article covers real vineyard case studies from Germany, Italy, California, and New Zealand, plus the role of custom drone software in precision winemaking.
ArduPilot Drone Solutions for Agriculture Modern agriculture demands more than manual scouting and uniform input application. This article presents three detailed drone use cases built on the open-source ArduPilot firmware and Mission Planner ground station: multispectral vineyard health monitoring with MicaSense RedEdge-P sensors and terrain-following flight on sloped terrain, variable-rate prescription mapping for broadacre crops using VTOL platforms and RTK GPS, and autonomous livestock headcount verification with onboard AI detection running on NVIDIA Jetson companion computers. Each case specifies the hardware architecture, Mission Planner configuration, and custom software modules developed by A-Bots.com to bridge raw aerial data and actionable farm decisions.
Drone Solutions for Energy Infrastructure Energy infrastructure inspection is shifting from helicopter patrols and climbing crews to automated drone workflows. This article details three production-ready use cases built on ArduPilot firmware and Mission Planner: radiometric thermal inspection of utility-scale solar farms with IEC 62446-3 compliance and AI-powered defect classification, LiDAR-based power line corridor mapping with vegetation clearance analysis and digital twin generation, and BVLOS pipeline surveillance with onboard optical gas imaging and real-time methane leak alerting. Each case specifies hardware architecture, ArduPilot parameters, Mission Planner configuration, and custom software modules developed by A-Bots.com for seamless integration with existing CMMS and regulatory reporting systems.
Ardupilot Drone Solutions: Construction Mining SAR Construction sites, mining operations, and search-and-rescue missions share a common need for frequent, accurate aerial data delivered faster than traditional methods allow. This final article in a three-part series details three production-ready drone use cases built on ArduPilot and Mission Planner: weekly photogrammetric construction progress monitoring with automated BIM overlay and cut-fill volumetrics, mining stockpile and pit progression surveys using RTK-enabled LiDAR with slope stability tracking, and thermal search-and-rescue operations with real-time AI human detection on NVIDIA Jetson companion computers. Each case specifies hardware, firmware parameters, and custom software developed by A-Bots.com.
Bluetooth and UWB Item Trackers 2026: AirTag vs SmartTag The smart tracker market surpassed $856 million in 2025 and continues to grow rapidly as consumers and businesses adopt Bluetooth and UWB tracking solutions. This article examines the technical architecture behind modern item trackers, including BLE crowdsourced networks, Ultra-Wideband precision finding, and the DULT anti-stalking standard. It provides a detailed comparison of Apple AirTag 2, Samsung Galaxy SmartTag 2, and Tile Pro across key metrics such as range, battery life, accuracy, network size, and privacy safeguards. The article also explores practical use cases from luggage tracking to bicycle theft prevention and highlights opportunities in custom tracking app development for businesses entering this space.
Top stories
Copyright © Alpha Systems LTD All rights reserved.
Made with ❤️ by A-BOTS