Home
Services
About us
Blog
Contacts
Offline AI Chatbot: Complete Guide to Local AI Solutions
Section 1: Leading Offline AI Chatbot Applications
Section 2: Understanding Local Language Models for Offline AI Chatbot Systems
Section 3: Building Your Offline AI Chatbot—From Beginner Setup to Enterprise Solutions
Conclusion: The Future of Offline AI Chatbot Technology
Bonus: Build an Offline AI Chatbot (Beginner-Friendly, Minimal Coding)

The demand for privacy-focused artificial intelligence has pushed offline ai chatbot technology from niche experimental tools into practical solutions for businesses and individuals. Unlike cloud-based systems that transmit every conversation to remote servers, an offline ai chatbot processes all interactions locally on your device, ensuring complete data privacy and independence from internet connectivity.
The market shift toward offline ai chatbot solutions reflects growing concerns about data security and operational reliability. Healthcare providers handling patient information, financial institutions managing sensitive transactions, and defense contractors working with classified data increasingly require systems that function without exposing information to external networks. Beyond security considerations, offline ai chatbot applications serve users in remote locations where internet access remains unreliable or unavailable—from research stations in Antarctica to rural clinics in developing regions.
This comprehensive guide examines the current landscape of offline ai chatbot technology, covering ready-to-use applications, the language models that power them, and practical implementation steps for both beginners and organizations requiring enterprise-grade custom solutions.
Section 1: Leading Offline AI Chatbot Applications
Choosing the right offline ai chatbot software depends on your technical comfort level and specific requirements. While dozens of tools claim to offer local AI functionality, two applications stand out for reliability and ease of use.
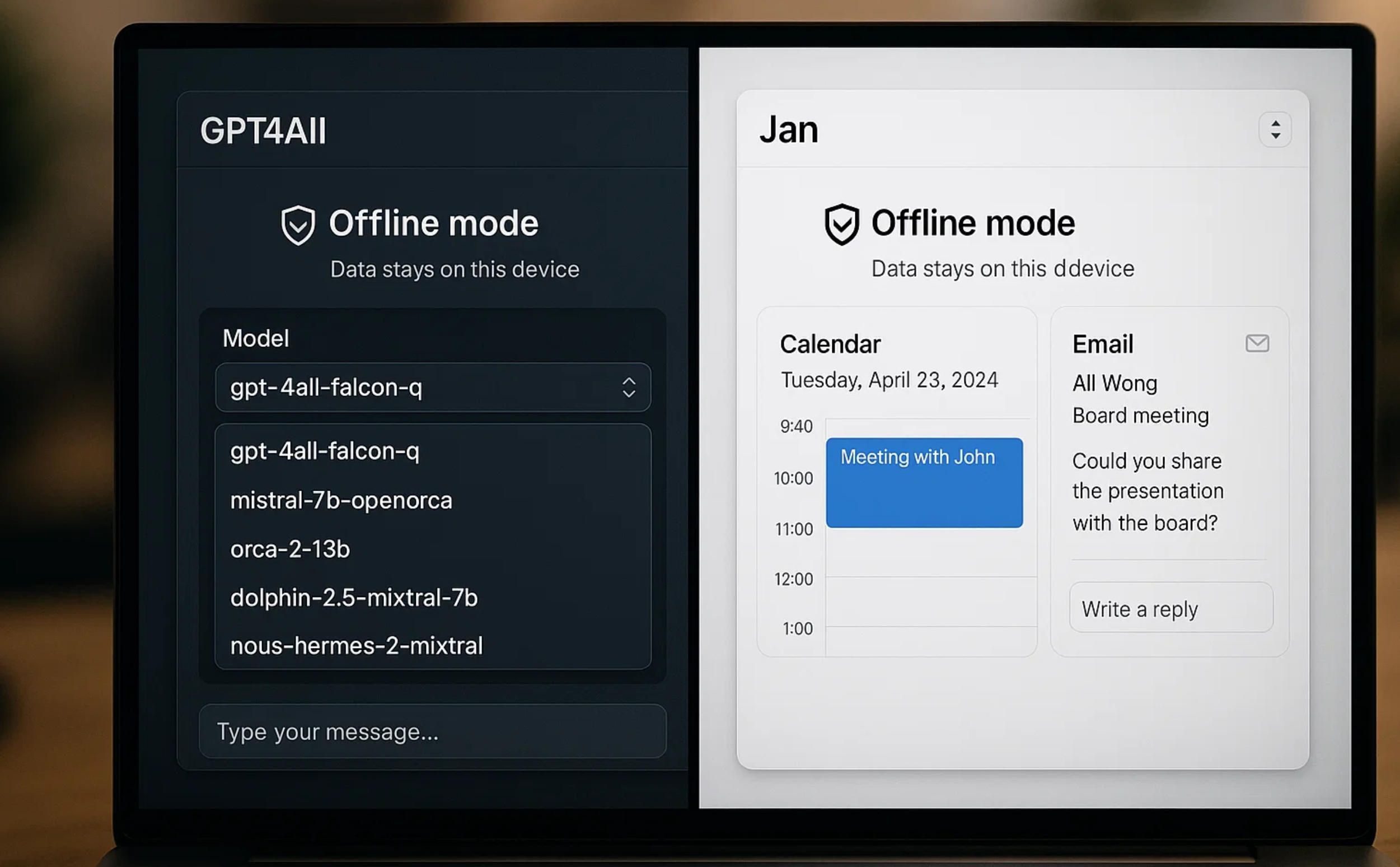
GPT4All: Privacy-Focused Desktop Solution
GPT4All, developed by Nomic AI, represents the most accessible entry point for users seeking a fully functional offline ai chatbot without technical complexity. The application runs entirely on consumer-grade hardware, requiring no specialized equipment or programming knowledge.
The installation process takes under fifteen minutes. After downloading the platform-specific installer for Windows, macOS, or Linux, users launch the application and select from hundreds of pre-configured language models. GPT4All automatically handles model optimization for your hardware, adjusting processing between CPU and GPU resources to maximize performance. The system requires between 8GB and 16GB of RAM depending on the selected model, with most installations consuming 4GB to 7GB of storage space.
What distinguishes GPT4All as an offline ai chatbot solution is its LocalDocs feature, which allows users to connect the chatbot to private document collections stored locally. This means the system can reference your proprietary information, company manuals, or personal notes during conversations without ever uploading files to external servers. The MIT-licensed open-source codebase provides full transparency, allowing security audits by in-house teams or independent reviewers.
GPT4All supports leading model architectures including LLaMa, Mistral, Nous-Hermes, and DeepSeek R1. Users can switch between models instantly to compare performance on different tasks, from technical documentation to creative writing. The chat interface mirrors familiar cloud services while maintaining zero network dependencies once models are downloaded.
Jan: Cross-Platform Local AI with Extended Integration
Jan emerged as a streamlined alternative for users who want their offline ai chatbot integrated more deeply with daily workflows. Built on the same underlying technology as GPT4All (llama.cpp inference engine), Jan focuses on user experience and connectivity to existing productivity tools.
The platform differentiates itself through native integrations with email clients, calendar systems, and file management applications. While the offline ai chatbot core operates without internet, Jan can optionally synchronize context from connected services, allowing the AI to reference your schedule, recent correspondence, and document library during interactions. Users maintain granular control over which data sources the chatbot accesses.
Jan's interface emphasizes conversation continuity—the system maintains context across sessions, remembering previous discussions and user preferences without requiring manual configuration. This persistent memory lives entirely on your device, encrypted and inaccessible to external services. The application runs on Windows, macOS, and Linux with consistent functionality across platforms.
For developers and power users, Jan provides a local API endpoint, enabling custom applications to leverage the offline ai chatbot capabilities through standard HTTP requests. This architectural decision allows integration with existing business software without modifying the core chatbot system. Organizations can build proprietary interfaces while keeping all AI processing air-gapped from their network infrastructure.
Both GPT4All and Jan support the GGUF model format, the current standard for quantized language models optimized for consumer hardware. This compatibility ensures users can source models from the broader open-source community, including specialized variants trained for specific domains like legal analysis, medical information, or software development.
Section 2: Understanding Local Language Models for Offline AI Chatbot Systems
The effectiveness of any offline ai chatbot depends fundamentally on the underlying language model. Unlike cloud services that can dynamically allocate massive computational resources, local systems must balance model capability against hardware constraints. Understanding model architecture and quantization techniques helps users and developers make informed choices about which models suit specific use cases.
Model Size and Capability Trade-offs
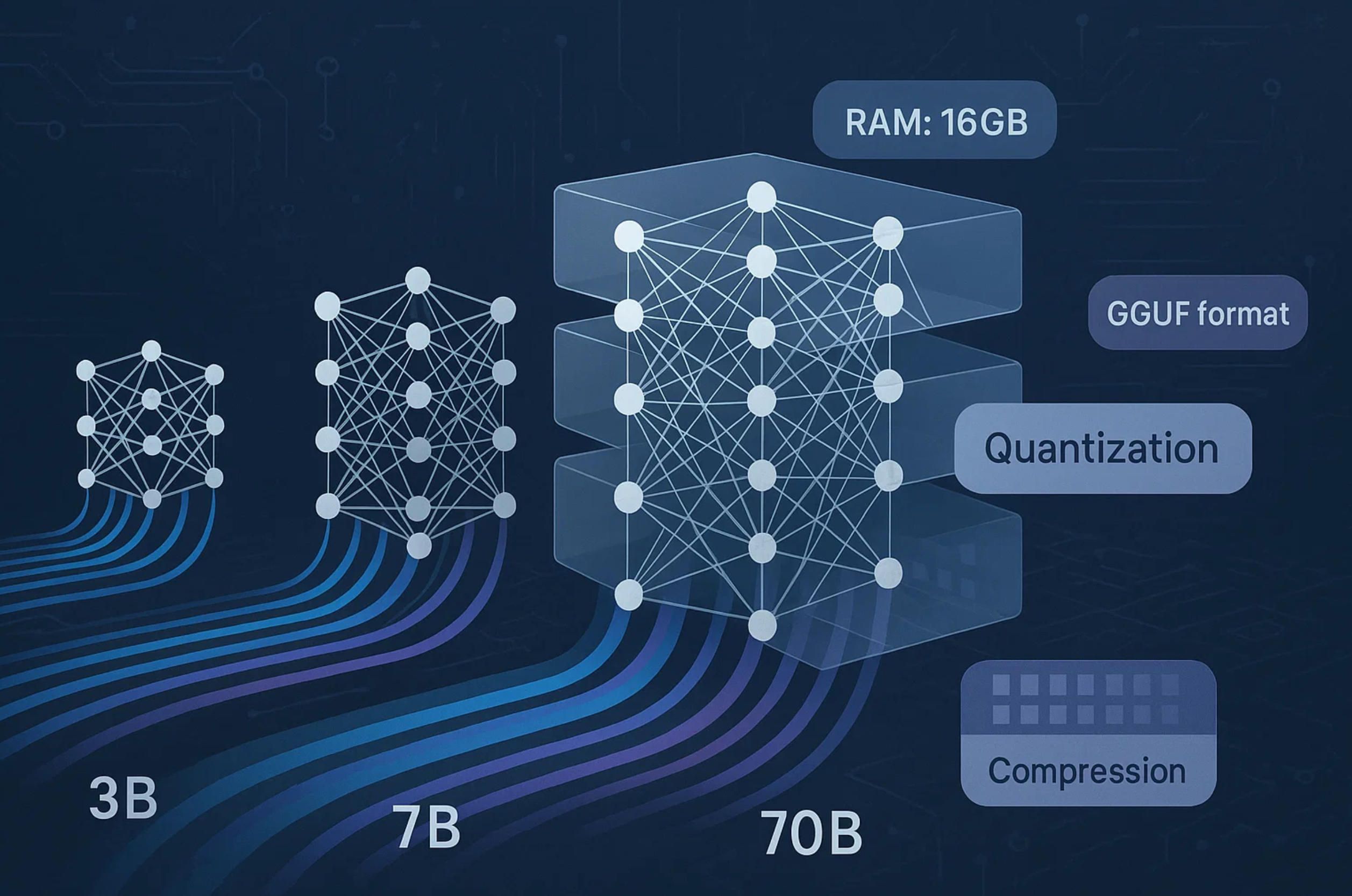
Language models are typically designated by parameter count—the "B" notation indicating billions of parameters that define the model's learned knowledge. A 7B model contains seven billion parameters, while a 70B model has ten times that complexity. Larger models generally produce more nuanced, contextually appropriate responses but demand proportionally more RAM and processing power.
For practical offline ai chatbot deployment, the relationship between model size and hardware capacity follows these approximate guidelines:
Small models (1B-3B parameters): These lightweight options run smoothly on devices with 8GB RAM, including many laptops manufactured within the past five years. They handle straightforward tasks like answering factual questions, basic writing assistance, and simple conversation. Response quality noticeably degrades with complex reasoning or specialized knowledge domains. These models suit applications where speed matters more than sophistication—customer service scenarios with well-defined question categories or personal productivity tools with limited scope.
Medium models (7B-13B parameters): Representing the practical sweet spot for most offline ai chatbot implementations, medium-sized models require 16GB to 32GB RAM but deliver substantially better performance. They maintain context over longer conversations, handle multi-step reasoning tasks, and demonstrate competence across diverse subjects without specialized training. Organizations deploying offline ai chatbot solutions for internal knowledge management or customer support typically select models in this range, as they provide acceptable quality without requiring workstation-class hardware.
Large models (30B-70B+ parameters): These high-capability models demand 64GB RAM or more, often with GPU acceleration to achieve usable response speeds. The quality approaches cloud-based services like ChatGPT, with strong performance on complex analysis, technical writing, and domain-specific tasks. However, the hardware requirements limit offline ai chatbot applications using these models to server deployments or high-end workstations. Research institutions, enterprise R&D teams, and specialized applications justify the infrastructure investment when data security requirements prevent cloud usage.
Quantization: Making Models Hardware-Practical
Raw language models trained by research teams typically exist in formats requiring hundreds of gigabytes of storage and proportional processing resources. Quantization techniques compress these models by reducing numerical precision while preserving most capabilities. An offline ai chatbot using a quantized 7B model might occupy only 4GB of storage compared to 14GB for the original.
The GGUF format (GPT-Generated Unified Format) has become the standard for distributing quantized models compatible with consumer hardware. Different quantization levels offer varying trade-offs between size and quality. A Q4_0 quantization typically reduces model size by 75% with minimal quality loss for most tasks, making it the default choice for offline ai chatbot applications. More aggressive Q2 quantization cuts size further but introduces noticeable degradation in response coherence.
Leading Open-Source Models for Local Deployment
The open-source community has produced several model families particularly suited to offline ai chatbot use:
LLaMa 3 series: Meta's LLaMa models set performance standards for open-source language AI. LLaMa 3 demonstrates strong multi-language support and maintains context effectively across extended conversations. The 8B variant runs efficiently on mid-range hardware while delivering quality comparable to much larger proprietary models. LLaMa 3's training included extensive instruction-following datasets, making it naturally conversant without requiring additional fine-tuning for basic chatbot applications.
Mistral 7B: This French-developed model architecture achieves exceptional performance relative to its compact size. Mistral employs sliding window attention mechanisms that allow it to process longer input contexts than models with similar parameter counts. For offline ai chatbot systems handling lengthy documents or complex multi-turn conversations, Mistral's architecture provides practical advantages. The model's commercial-friendly license permits unrestricted business use, unlike some alternatives with restrictive terms.
Phi-3 family: Microsoft's Phi series targets the lower end of the capability spectrum, with models as small as 3.8B parameters that nonetheless perform surprisingly well on reasoning tasks. These models resulted from carefully curated training data rather than simply processing massive datasets. For offline ai chatbot applications on resource-constrained hardware—tablets, older laptops, or embedded systems—Phi models offer usable functionality where larger alternatives would be impractical.
DeepSeek Coder variants: Specialized models optimized for programming tasks demonstrate how fine-tuning can make smaller models highly effective in narrow domains. An offline ai chatbot built around DeepSeek Coder can assist with code generation, debugging, and documentation at a level approaching larger general-purpose models, while requiring only 7B parameter capacity.
Sourcing and Evaluating Models
HuggingFace serves as the primary distribution platform for open-source language models. The repository hosts thousands of model variants, with detailed information about training methodology, licensing terms, and quantization formats. When selecting a model for an offline ai chatbot project, several factors merit evaluation beyond raw parameter count.
Benchmark scores provide quantitative comparison across models, but real-world performance often depends on how closely your use case aligns with the model's training. Models trained primarily on English text may struggle with multilingual conversations. Models optimized for instruction-following excel at task-oriented dialogue but might produce less natural casual conversation than models trained on diverse internet text.
License terms vary significantly. Some models permit only research use, while others allow unrestricted commercial deployment. Organizations building offline ai chatbot products must verify that selected models carry appropriate licenses for their intended use. The open-source community generally favors Apache 2.0 and MIT licenses, which impose minimal restrictions, but several prominent models use custom licenses with specific limitations.
Regular model releases and updates create a rapidly evolving landscape. As of early 2025, researchers continue publishing new architectures and training techniques that improve efficiency and capability. An offline ai chatbot development strategy should anticipate model upgrades as improved versions become available, designing systems to swap model backends without requiring application rewrites.

Section 3: Building Your Offline AI Chatbot—From Beginner Setup to Enterprise Solutions
Creating an offline ai chatbot ranges from straightforward installation for personal use to complex custom development for organizational deployment. This section provides practical guidance for both scenarios.
Getting Started: Zero-Code Implementation
Non-technical users can deploy a functional offline ai chatbot in under an hour using either GPT4All or Jan. The process requires no programming knowledge or command-line interaction.
Step 1: Verify Hardware Requirements Check your computer specifications before downloading any software. Open your system information panel (Windows: Settings > System > About; macOS: Apple menu > About This Mac). Confirm you have at least 16GB of RAM and 20GB of available storage space. Note your processor type—modern Intel or AMD chips from the past five years typically support the required instruction sets (AVX2), while Apple Silicon M-series processors work without concerns.
Step 2: Download and Install Application Visit the official GPT4All website (nomic.ai/gpt4all) or Jan website (jan.ai) and download the installer for your operating system. Run the downloaded file and follow the installation wizard. The process installs the core application framework but not the language models themselves—those download separately in the next step.
Step 3: Select and Download Language Model After launching the application for the first time, you'll see a model library. For your first offline ai chatbot experience, select a recommended 7B model like "Mistral-7B-Instruct" or "Llama-3-8B-Instruct." The download typically takes 10-30 minutes depending on connection speed, as models range from 4GB to 8GB. The application shows download progress and automatically installs the model when complete.
Step 4: Configure Basic Settings Open the settings panel to adjust temperature (response randomness) and context window (conversation memory). Default settings work well for most users, but experimentation helps optimize performance for your preferences. Temperature values between 0.3 and 0.7 balance consistency with creativity. Higher context windows allow the offline ai chatbot to remember more conversation history but increase processing time.
Step 5: Test and Evaluate Start a conversation to test your offline ai chatbot. Try diverse queries to understand its capabilities and limitations. Ask factual questions, request writing assistance, and test its handling of multi-step tasks. If performance seems slow, consider switching to a smaller model or adjusting settings to reduce context length.
This basic setup serves personal productivity needs, learning applications, and experimentation with local AI. Users can add multiple models and switch between them based on specific tasks—using a code-specialized model for programming help, then switching to a general-purpose model for other queries.

When Professional Development Becomes Necessary
While consumer applications like GPT4All and Jan provide impressive functionality, certain use cases demand custom offline ai chatbot development with professional expertise. Organizations face these limitations with off-the-shelf solutions:
Mobile Platform Requirements: Neither GPT4All nor Jan offers native mobile applications optimized for iOS and Android. Businesses needing offline ai chatbot functionality on mobile devices require custom development that addresses the unique constraints of mobile hardware—limited RAM, battery efficiency considerations, and touch-optimized interfaces. Mobile development also involves platform-specific optimizations and integration with device capabilities like voice input and camera access.
Enterprise System Integration: Commercial offline ai chatbot deployments often need deep integration with existing enterprise software—CRM systems, custom databases, proprietary document management platforms, and legacy applications. Off-the-shelf solutions provide basic file access but lack the architectural flexibility for complex enterprise environments. Custom development enables the chatbot to interact with business systems programmatically, automatically pulling relevant context and pushing structured outputs to appropriate destinations.
Specialized Model Fine-tuning: Generic language models lack domain-specific knowledge for specialized industries. A medical offline ai chatbot needs familiarity with clinical terminology, drug interactions, and diagnostic protocols. Legal applications require understanding of case law and regulatory frameworks. Fine-tuning models on proprietary data produces dramatically better results than generic alternatives, but requires machine learning expertise and computational resources beyond consumer equipment.
Security and Compliance Requirements: Regulated industries face strict requirements around data handling, audit trails, and access controls. Healthcare organizations must comply with HIPAA regulations, financial services with SOX requirements, and government contractors with NIST security frameworks. Custom offline ai chatbot development implements necessary security controls, logging mechanisms, and compliance features that consumer applications cannot address.
Performance Optimization: Production deployments serving hundreds of concurrent users need optimization beyond what general-purpose applications provide. Custom solutions can implement model quantization strategies tuned to specific hardware, request queuing mechanisms, and caching layers that dramatically improve response times and system capacity.
A-Bots.com: Expert Custom Offline AI Chatbot Development
Organizations requiring enterprise-grade offline ai chatbot solutions benefit from partnering with experienced development teams like A-Bots.com. With proven expertise in mobile application development and AI integration, A-Bots.com delivers custom solutions addressing the specific challenges of offline AI deployment.
The A-Bots.com development process begins with thorough requirements analysis, identifying the exact use cases, performance expectations, and integration needs for your offline ai chatbot. This discovery phase ensures alignment between technical capabilities and business objectives, preventing costly mid-project course corrections.
Architecture design follows discovery, where engineers specify the technology stack, model selection, and system integration points. A-Bots.com's approach emphasizes modularity, allowing future model upgrades without requiring application rewrites. The team has extensive experience with both iOS and Android development, ensuring native performance and user experience on mobile platforms.
Implementation includes not just the offline ai chatbot core but comprehensive testing across edge cases and performance scenarios. A-Bots.com conducts security audits, performance profiling, and usability testing to validate the solution meets production requirements. The team documents the system architecture and provides training to ensure your staff can maintain and extend the application long-term.
For organizations exploring offline ai chatbot technology, A-Bots.com offers consultation services to assess feasibility, estimate development scope, and recommend appropriate approaches. Whether you need a mobile application with embedded AI, a desktop solution with complex integrations, or testing and optimization of an existing implementation, A-Bots.com's expertise ensures successful deployment.

Conclusion: The Future of Offline AI Chatbot Technology
The offline ai chatbot landscape continues maturing rapidly, with improving model efficiency and decreasing hardware requirements making local AI accessible to broader audiences. Recent advances in model compression and inference optimization mean that devices considered inadequate last year now run capable language models smoothly.
For individuals and organizations prioritizing data privacy, operational independence, or deployment in connectivity-challenged environments, offline ai chatbot solutions provide practical alternatives to cloud services. The choice between consumer applications and custom development depends on specific requirements—casual users find ready-made solutions sufficient, while businesses with specialized needs benefit from professional development expertise.
Whether implementing a simple personal assistant or deploying an enterprise-grade offline ai chatbot system across your organization, understanding the technology landscape, model options, and development approaches ensures successful outcomes. The tools and knowledge exist today to build sophisticated local AI systems that rival cloud alternatives while maintaining complete control over your data and conversations.

Bonus: Build an Offline AI Chatbot (Beginner-Friendly, Minimal Coding)
This guide shows two simple paths to a fully offline chatbot on your computer:
- Option A (fastest): Terminal chatbot with Ollama + a small local LLM
- Option B (still easy): Local web UI using Streamlit + Ollama
You don’t need cloud keys or advanced ML skills. After the initial downloads, everything runs offline.
What You’ll Need
- OS: Windows, macOS, or Linux
- Hardware: 8–16 GB RAM recommended (3B–8B models work on CPU; GPU optional)
- Python: 3.10+
- Disk space: 5–10 GB free for models and embeddings
Tip: If your machine is modest, pick a smaller model (e.g., llama3.2:3b) first.
Install Ollama (once)
-
Download & install: https://ollama.com/
-
Open a terminal and pull a compact chat model:
ollama pull llama3.2:3b
You can test it right away:
ollama run llama3.2:3b
Type exit to quit the REPL.
Option A — Terminal Chatbot (5–10 minutes)
1) Create a project folder
mkdir offline-chat
cd offline-chat
2) Make a Python virtual environment
python -m venv .venv
# Windows:
.venv\Scripts\activate
# macOS/Linux:
source .venv/bin/activate
3) Install the only package we need
pip install ollama
4) Minimal chatbot with conversation memory
Create chat.py:
# chat.py
import json, os, ollama
MODEL = "llama3.2:3b"
HISTORY_FILE = "history.json"
history = []
if os.path.exists(HISTORY_FILE):
try:
history = json.load(open(HISTORY_FILE, "r", encoding="utf-8"))
except Exception:
history = []
print("Offline chatbot ready. Type 'exit' to quit, 'clear' to forget memory.\n")
while True:
q = input("You: ").strip()
if q.lower() in {"exit", "quit"}:
break
if q.lower() == "clear":
history = []
json.dump(history, open(HISTORY_FILE, "w", encoding="utf-8"))
print("Memory cleared.\n")
continue
messages \= history \+ \[{"role": "user", "content": q}\]
resp \= ollama.chat(model=MODEL, messages=messages)
answer \= resp\["message"\]\["content"\]
print("\\nBot:", answer, "\\n")
\# Persist memory
history \= messages \+ \[resp\["message"\]\]
json.dump(history, open(HISTORY\_FILE, "w", encoding="utf-8"))
5) Run it
python chat.py
You now have a private, offline chatbot with simple memory (stored in history.json).
Switching models:
ollama pull mistral:7b-instruct
# then set MODEL = "mistral:7b-instruct" in chat.py
Option B — Local Web UI with Streamlit (10–15 minutes)
1) Setup
From your project folder / venv:
pip install streamlit ollama
2) Create app.py
# app.py
import streamlit as st
import ollama
st.set_page_config(page_title="Offline Chatbot", page_icon="💬", layout="centered")
MODEL = "llama3.2:3b"
if "chat" not in st.session_state:
st.session_state.chat = [{"role": "assistant", "content": "Hi! I'm your offline chatbot."}]
st.title("💬 Offline AI Chatbot")
st.caption("Runs fully on your machine via Ollama. No cloud keys needed.")
for msg in st.session_state.chat:
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
prompt = st.chat_input("Type your message…")
if prompt:
st.session_state.chat.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
with st.chat\_message("assistant"):
with st.spinner("Thinking locally…"):
resp \= ollama.chat(model=MODEL, messages=st.session\_state.chat)
answer \= resp\["message"\]\["content"\]
st.markdown(answer)
st.session\_state.chat.append({"role": "assistant", "content": answer})
# Small sidebar extras
with st.sidebar:
st.subheader("Settings")
model = st.text_input("Model", MODEL, help="e.g., llama3.2:3b, mistral:7b-instruct")
if model and model != MODEL:
st.session_state.chat.append({"role": "assistant", "content": f"Switched model to `{model}`."})
MODEL = model
if st.button("Clear chat"):
st.session_state.chat = [{"role":"assistant","content":"Chat cleared. How can I help?"}]
3) Run the app
streamlit run app.py
A browser tab will open at http://localhost:8501. Everything stays local.
Chat with Your Local PDF (RAG-Lite, ~10 minutes)
This adds simple “chat over documents” while staying offline.
1) Install extras
pip install langchain chromadb pypdf
ollama pull nomic-embed-text
2) Create rag.py
# rag.py
import os
import ollama
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
DB_DIR = "chroma_db"
EMBED_MODEL = "nomic-embed-text"
CHAT_MODEL = "llama3.2:3b"
def embed(texts):
# Batch-embed via Ollama embeddings endpoint
res = ollama.embeddings(model=EMBED_MODEL, prompt="\n\n".join(texts))
# Ollama returns a single embedding for whole prompt; we’ll do per-chunk calls instead:
embeds = []
for t in texts:
e = ollama.embeddings(model=EMBED_MODEL, prompt=t)["embedding"]
embeds.append(e)
return embeds
def build_or_load_db(pdf_path):
os.makedirs(DB_DIR, exist_ok=True)
# Load & split
docs = PyPDFLoader(pdf_path).load()
splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=150)
chunks = splitter.split_documents(docs)
\# Prepare plain texts for manual embedding
texts \= \[c.page\_content for c in chunks\]
vectors \= \[ollama.embeddings(model=EMBED\_MODEL, prompt=t)\["embedding"\] for t in texts\]
\# Store in Chroma with explicit embeddings
from chromadb import PersistentClient
client \= PersistentClient(path=DB\_DIR)
coll \= client.get\_or\_create\_collection("docs")
\# Clear & insert
try:
client.delete\_collection("docs")
coll \= client.get\_or\_create\_collection("docs")
except Exception:
pass
coll.add(documents=texts, embeddings=vectors, ids=\[f"id\_{i}" for i in range(len(texts))\])
return coll
def retrieve(coll, query, k=4):
q_emb = ollama.embeddings(model=EMBED_MODEL, prompt=query)["embedding"]
res = coll.query(query_embeddings=[q_emb], n_results=k)
return res.get("documents", [[]])[0]
if __name__ == "__main__":
pdf = "your.pdf" # put a PDF file in the same folder
coll = build_or_load_db(pdf)
print("RAG ready. Ask about the PDF (type 'exit' to quit).")
history \= \[\]
while True:
q \= input("\\nYou: ").strip()
if q.lower() in {"exit", "quit"}:
break
ctx\_docs \= retrieve(coll, q, k=4)
context \= "\\n\\n".join(ctx\_docs)
prompt \= f"Use ONLY the context to answer.\\n\\nContext:\\n{context}\\n\\nQuestion: {q}"
resp \= ollama.chat(model=CHAT\_MODEL, messages=\[\*history, {"role":"user","content":prompt}\])
answer \= resp\["message"\]\["content"\]
print("\\nBot:", answer)
history \+= \[{"role":"user","content":q},{"role":"assistant","content":answer}\]
3) Run it
python rag.py
Ask questions about your PDF; the bot answers using retrieved chunks, locally.
Troubleshooting
- Too slow / out of memory? Try a smaller model like
llama3.2:3bor evenllama3.2:1b. - First run needs internet to download the model once. After that, you can go fully offline.
- Better responses: give the model concise prompts and keep conversations focused.
- GPU optional: CPU is fine for small models; a GPU speeds things up.
Where to Go Next
-
Package this into a desktop app (Tauri/Electron) or a mobile app (Flutter/React Native) that ships with a local model download step.
-
Need a polished, branded offline AI assistant for customers or field teams? A-Bots.com can turn this prototype into a production-grade mobile or desktop app with secure local storage, on-device fine-tuning, and RAG over your private docs.
✅ Hashtags
#OfflineAI
#AIchatbot
#LocalLLM
#PrivacyAI
#GPT4All
#JanAI
#OnDeviceAI
#OpenSourceAI
#ChatbotDevelopment
#AIwithoutInternet
#EnterpriseChatbot
#CustomAIDevelopment
Other articles
Custom Offline AI Chat Apps Development From offshore ships with zero bars to GDPR-bound smart homes, organisations now demand chatbots that live entirely on the device. Our in-depth article reviews every major local-LLM toolkit, quantifies ROI across maritime, healthcare, factory and consumer sectors, then lifts the hood on A-Bots.com’s quantisation, secure-enclave binding and delta-patch MLOps pipeline. Learn how we compress 7-B models to 1 GB, embed your proprietary corpus in an offline RAG layer, and ship voice-ready UX in React Native—all with a transparent cost model and free Readiness Audit.
Offline AI Chatbot Development Cloud dependence can expose sensitive data and cripple operations when connectivity fails. Our comprehensive deep-dive shows how offline AI chatbot development brings data sovereignty, instant responses, and 24 / 7 reliability to healthcare, manufacturing, defense, and retail. Learn the technical stack—TensorFlow Lite, ONNX Runtime, Rasa—and see real-world case studies where offline chatbots cut latency, passed strict GDPR/HIPAA audits, and slashed downtime by 40%. Discover why partnering with A-Bots.com as your offline AI chatbot developer turns conversational AI into a secure, autonomous edge solution.
Offline-AI IoT Apps by A-Bots.com 2025 marks a pivot from cloud-first to edge-always. With 55 billion connected devices straining backhauls and regulators fining data leaks, companies need AI that thinks on-device. Our long-read dives deep: market drivers, TinyML runtimes, security blueprints, and six live deployments—from mountain coffee roasters to refinery safety hubs. You’ll see why offline inference slashes OPEX, meets GDPR “data-minimization,” and delivers sub-50 ms response times. Finally, A-Bots.com shares its end-to-end method—data strategy, model quantization, Flutter apps, delta OTA—that keeps fleets learning without cloud dependency. Perfect for CTOs, product owners, and innovators plotting their next smart device.
Tome App vs SlidesAI A hands-on, 3-section deep dive that pits Tome App vs SlidesAI across setup, narrative refinement, and team-scale governance—so you’ll know exactly which AI deck builder speeds your next pitch. (Spoiler: if you need something custom, A-Bots.com can craft it.)
Wiz AI Chat Bot Wiz AI isn’t just another chatbot tool — it’s a full-stack voice automation platform built for Southeast Asia’s linguistic and cultural complexity. In this comprehensive, no-fluff guide, we walk you through the entire lifecycle of creating and deploying a human-like conversational agent using Wiz AI. Learn how to build natural call flows, manage multilingual NLP, personalize in real time, and activate smart triggers that behave like skilled agents. We also explore the hidden features that turn ordinary users into AI power designers — from behavioral analytics to UX timing control. And if you need a truly custom solution, A-Bots.com can help you go even further
Coffee Shop App Development Company Comprehensive guide to coffee shop app development featuring detailed case studies of Scooter Coffee app and Biggby Coffee app implementations. Learn essential features including mobile ordering, payment integration, and loyalty programs that increase customer spending by 67%. Explore coffee shop finder technology and revolutionary cryptocurrency rewards concepts. Expert analysis of technical architecture, security, and testing protocols. Partner with A-Bots.com for custom development, blockchain integration, or QA services. The coffee apps market projected to reach $390M by 2033 with 14.9% annual growth.
AI Chatbot Offline Capabilities for Mission-Critical Edge Apps Cloud dropouts, privacy mandates, and mission-critical workflows expose a hard truth: traditional chatbots collapse when the signal dies. This in-depth guide unpacks the engineering science behind AI chatbot offline capabilities—model compression, encrypted vector stores, smart sync—and shows how they translate into real-world wins across aviation, maritime, healthcare, agriculture, manufacturing, energy, hospitality, and disaster response. You’ll follow A-Bots.com’s proven delivery pipeline from discovery workshop to edge deployment, understand governance safeguards for HIPAA and GDPR, and explore dozens of use-case vignettes where on-device NLP guides crews, clinicians, and field technicians without ever asking for a bar of coverage. If your organisation depends on uninterrupted dialogue, this article maps the path to a robust, compliant, offline-first assistant—ready to launch with A-Bots.com, your trusted chatbot development company.
Top stories
Copyright © Alpha Systems LTD All rights reserved.
Made with ❤️ by A-BOTS