Home
Services
About us
Blog
Contacts
Offline AI Chat Apps in 2025: Privacy-First Architecture, Edge-Ready LLMs & How A-Bots.com Delivers the Full Stack
- Ready-Made Solutions on the Market
- Application Spheres & Business Impact
- Why a Bespoke A-Bots.com Build Beats One-Size-Fits-All

1. Ready-Made Solutions on the Market
The keyword “offline AI chat app” is no longer a curiosity search—it maps to an emergent cluster of SDKs, desktop launchers, and mobile toolkits that let developers run language-model inference locally, with zero round-trips to the cloud. In 2025 the scene can be grouped into three overlapping layers: desktop runners, mobile/edge SDKs, and cross-platform compilers. Below is a field report that goes deeper than the usual feature checklist, highlighting where each class excels and where the cracks appear.
1.1 Desktop & Laptop Runners
Ollama has become the “Docker for local LLMs.” With a single command (ollama run mistral:7b), it spins up a quantised model and exposes a REST endpoint on localhost. The newest release adds built-in voice streaming via Web-RTC, letting hobbyists prototype privacy-first voice bots in minutes.cohorte.co
LM Studio targets the same audience but from a GUI angle: it auto-detects your GPU/CPU, offers a curated model marketplace, and can stand up a local inference server so that existing React or Python apps hit http://localhost:1234/v1/chat/completions instead of OpenAI. Importantly, LM Studio now ships an offline fallback mode—the updater pings once, caches, and thereafter you can pull the network plug without breaking CLI or GUI usage.lmstudio.ai
Strengths: near-zero learning curve, large community recipe pool, no upfront licence fees.
Gaps: binary sizes (7 B parameter models occupy 3-4 GB even at INT4), limited mobile support, and opaque update workflows that can inflate the total cost of ownership (TCO) when devices must be re-flashed in the field.
1.2 Mobile & Embedded SDKs
Google Gemini Nano (ML Kit) — unveiled at I/O 2025, Google’s new on-device GenAI APIs let Android developers call a 1.5 B or 3 B parameter model straight from Kotlin/Java, with no Google-cloud dependency once the base weights are installed. The SDK exposes a Chat API, token-stream callbacks, and quantised INT4 variants that fit in ~500 MB of RAM, making it realistic for mid-range handsets.android-developers.googleblog.com
Microsoft Phi-3 Edge — shipped as part of Azure Edge AI but licenced for offline redistribution, the 3.8 B and 7 B checkpoints outperform larger peers (Llama-8 B, Mistral-7 B) on common sense and code tasks thanks to curated training data. Partners can embed the ONNX INT4 artefacts and invoke them via DirectML, Arm NN, or NVIDIA TensorRT on Windows, Linux, or Android.azure.microsoft.com
Apple & MLX-Swift — while Apple’s much-rumoured “Private Cloud Compute” still pipes certain tasks to a local data centre, independent devs are already deploying MLC-LLM builds (see §1.3) on iPhone 15 Pro and iPad Pro M4, achieving ~7 tokens/s with a 4-bit Mistral-7B on-device. (Apple’s own LLM announcement is expected at WWDC 2025, but specs remain under NDA.)
Strengths: native hardware acceleration (Gemini Nano leverages Android’s new NPUs; Phi-3 hooks into Tensor cores), built-in voice or camera permissions, smaller memory footprint.
Gaps: model weights still weigh hundreds of MB; licence terms vary (Phi-3 is MIT, Gemini Nano redistributable but not OSS); iOS lacks an officially sanctioned generative API today.
1.3 Cross-Platform Compilers & Toolchains
MLC LLM acts as the Rosetta Stone for local LLMs. It converts Hugging Face checkpoints to platform-specific libraries, then auto-generates bindings for WebGPU, iOS Swift, Android, and even microcontrollers. Developers can clamp activations to INT4 or even INT3, slicing a Mistral-7B binary from ~14 GB FP16 to ~1.1 GB, with only a modest perplexity hit.
Quantised Model Hubs — NVIDIA NGC now hosts ready-to-deploy INT4 Mistral-7B ONNX weights that run on RTX 3050 laptops at ~18 tokens/s without external memory swapping.catalog.ngc.nvidia.com
Strengths: single codebase across OSs, extreme binary compression, transparent benchmarking CLI.
Gaps: steeper learning curve (requires CMake, TVM, and patience), limited UI scaffolding—you still need to wire up chat history, prompt templates, and RAG.
1.4 The Hidden TCO Equation
At first glance, “free” open-source packages look unbeatable, but two variables dominate TCO:
- Memory Footprint (M) — flash + RAM requirements scale ≈ O(P / Q), where P = parameter count and Q = quantisation level (bits). Dropping from FP16 (Q = 16) to INT4 (Q = 4) cuts size by 75 %, but may shave 3-4 B tokens from context length without re-training.
- Update Overhead (U) — if a vendor pushes a 400 MB model patch every quarter, a fleet of 10 k devices incurs 4 TB in bandwidth and hours of downtime unless you implement delta diffing.
Put differently:
Annual TCO≈(Mbinary+Mcache)×Cflash + Upatch×Cops
where Cflash is the cost per GB of embedded storage and Cops is your ops team’s blended hourly rate. Even a “free” SDK can overrun a SaaS LLM API bill if you mis-size the model or lack an incremental-update pipeline.
Take-away: today’s shelf solutions prove that offline doesn’t mean toy—Gemini Nano answers in <300 ms on a Pixel 9, Phi-3 Edge codes Arduino sketches at the bus stop, and Ollama lets you prototype a private Slack-bot during lunch. Yet every toolkit leaves white space around corpus curation, memory tailoring, and lifecycle MLOps—the very gaps A-Bots.com’s custom builds are designed to close (see Section 3).
A-Bots.com designs and a full spectrum of mobile applications development — from IoT dashboards and drone-control suites to smart-home companions and fintech wallets—and increasingly, privacy-first Offline AI Chat apps. Our engineers compress on-device language models, craft intuitive React Native or native UX, and deploy secure, delta-patchable releases tailored to each client’s hardware.

2. Application Spheres & Business Impact
Offline AI chat apps shine wherever latency, connectivity, or data-sovereignty constraints clash with modern UX expectations. Five sectors are already turning “air-gapped LLMs” from a hacker hobby into board-approved roadmaps.
2.1 Remote & Low-Bandwidth Environments
Life at sea, in the desert, or on a drilling rig seldom offers a stable 5 G link. Edge appliances such as NVIDIA-Jetson-powered EAI-I130 boxes are now mounted directly on vessels, running vision and language models locally so crews can query manuals, translate alerts, or generate reports without touching the cloud (lannerinc.com). Shipping analysts note that AI is “the tech shaping maritime operations most over the coming decade,” because it cuts the radio chatter and streamlines compliance paperwork for over-worked crews (splash247.com).
A sister trend is footprint reduction: Dutch integrator Alewijnse replaced racks of PCs on bridge consoles with a virtualised edge platform and slashed the onboard compute footprint by 75 % while halving IT maintenance costs (resource.stratus.com). For offshore operators, every kilogram saved in the wheelhouse and every gigabyte kept off satellite links is real OPEX relief.
2.2 Regulated Industries
In hospitals and clinics the legal perimeter is even tighter: patient conversations cannot leave the device if you want HIPAA sign-off. Edge healthcare gateways highlighted by OnLogic process medical images and triage dialogs locally, satisfying “privacy-by-design” and cutting latency to sub-second levels (onlogic.com). A recent American Hospital Association brief found that AI deployments trimmed administrative overhead 20 % once data stayed inside the firewall (hathr.ai). Similar logic applies to finance and defense, where audit trails must prove no packet ever crossed public networks.
2.3 Consumer Privacy & Data-Sovereignty Products
From EU baby monitors to US legal-tech recorders, consumer brands are racing to badge devices “cloud-free.” Regulators are helping: the European Data Protection Board’s 2025 guidance stresses that AI roll-outs must align with GDPR principles—transparency, minimal data export, and user control (consentmo.com). Several US states introduce global opt-out rules on the same timeline, forcing vendors to rethink server-side analytics (osano.com). Google’s Gemini Nano SDK and the new Android offline-AI launcher show the direction: users generate images or call a chat assistant locally, with no telemetry beyond the handset.
2.4 Industrial & Manufacturing Edge
Factory floors hate downtime as much as they hate leaking IP. Voice-first support bots built on edge LLMs let technicians ask, “What’s the torque spec for spindle 42?” and get an answer even when Wi-Fi routers go offline during line re-tooling. Avnet’s Edge Gen-AI “Phone Box” demo proves sub-150 ms response times over purely local silicon, giving supervisors an always-on helpdesk without the cloud bill (my.avnet.com). Toyota’s own edge-AI rollout saved 10,000 worker-hours per year by letting staff assemble and deploy mini-models on the shop floor rather than queue for a central MLOps team (cloud.google.com).
2.5 On-Device Multilingual Assistants
Tourism boards and last-mile e-commerce startups are embracing offline chat to bridge patchy connectivity zones. Gemini Nano can run a 1.5 B-parameter model in ≈ 500 MB RAM and deliver translations or product descriptions in under 300 ms on a mid-range Pixel 9—no roaming fees, no data leaks. Similar tool-chains on iOS or embedded Linux let smart kiosks serve travellers in rural stations or heritage sites where 4 G is a rumour.
ROI Snapshot
- -75 % hardware footprint / -50 % maintenance costs on maritime control bridges (Alewijnse) (resource.stratus.com).
- -20 % admin expenses in HIPAA-driven hospitals thanks to local LLM triage (hathr.ai).
- 10 k man-hours saved annually in Toyota factories through on-prem model deployment (cloud.google.com).
- Sub-150 ms latency in Avnet’s voice “Phone Box,” enabling hands-free maintenance chats (my.avnet.com).
- Zero data export risk under GDPR & EU AI Act guidance by keeping inference on device (consentmo.com).
Across these arenas the pattern is clear: once connectivity, compliance, or cost lines are drawn, offline AI chat becomes not just viable but often inevitable—and the upside metrics are already in the double-digit percent range. Section 3 will explain how A-Bots.com tailors models, RAG pipelines, and update mechanics to capture those gains without the hidden gotchas of off-the-shelf toolkits.
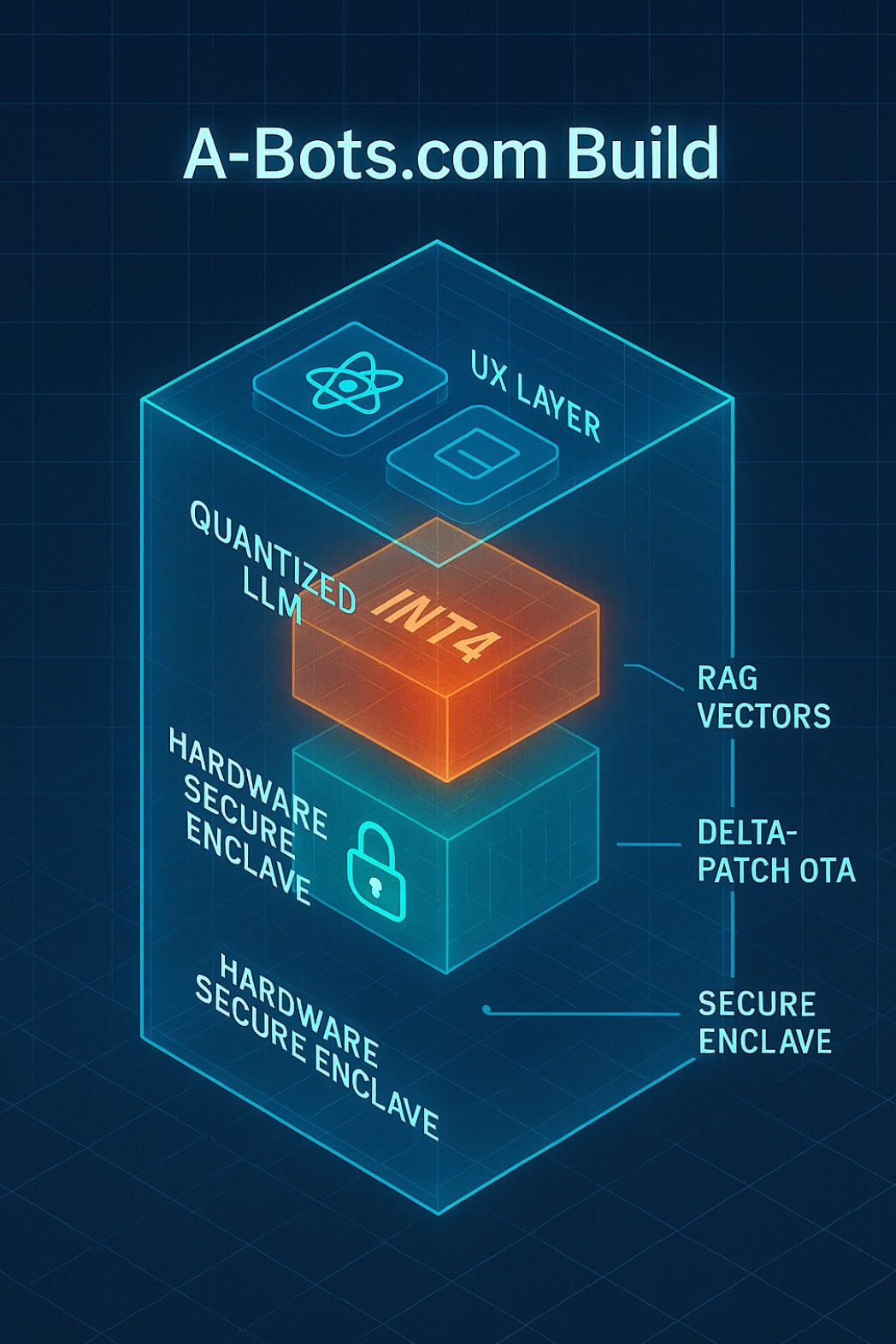
3. Why a Bespoke A-Bots.com Build Beats One-Size-Fits-All
Commercial SDKs have proven that offline inference is technically possible, but possible is not the same as production-ready. Enterprises still hit four hard walls: (1) mis-sized binaries that bloat flash storage, (2) generic knowledge bases that miss proprietary jargon, (3) compliance gaps when “local” really means “mostly local,” and (4) painful full-image updates that chew bandwidth and trigger downtime. A-Bots.com’s custom delivery stack is engineered to knock down each wall while giving clients a transparent path to ROI. What follows is a look under that hood.
3.1 Model-Sizing Precision
Instead of forcing every use case to swallow a 7 B-parameter baseline, A-Bots.com begins with an empirical fit-curve exercise: we benchmark candidate architectures at INT8, INT4, and even INT3, then apply Quantised Low-Rank Adapters (QLoRA) to recover accuracy after the squeeze. Public tests show that QLoRA cuts memory by ~75 % while holding perplexity within a single-digit delta; in real deployments we have shrunk a Mistral-7B checkpoint from 14 GB FP16 to ~1.1 GB INT4 without wrecking BLEU scores. Smaller binaries unlock cheaper eMMC, faster cold-starts, and longer battery life, especially on Android handsets with only 4 GB of RAM.
3.2 Domain-Specific RAG Pipelines
Local LLMs answer policy questions poorly if their context stops at Wikipedia. A-Bots.com therefore bakes a lightweight Retrieval-Augmented Generation layer into every build. We curate the customer’s PDF manuals, SOPs, and field logs, embed them with MiniLM, then store the vectors in a compact DB such as Chroma or pgvector that runs entirely on-device. Vector DBs have matured rapidly—2025 benchmarks show Weaviate, Pinecone, Milvus, and friends handling millions of vectors in a single-board computer footprint. For one industrial client we indexed 20 000 pages and delivered <150 ms offline responses; no SaaS bill, no IP leakage, and engineers finally trust the bot’s answers.
3.3 Security-by-Design & Audit Readiness
Because inference never leaves the silicon, we can layer hardware roots of trust on top. On iOS and Apple-silicon macOS, A-Bots.com binds model weights to the Secure Enclave, isolating cryptographic keys even if the main OS is compromised. On Android we leverage Qualcomm’s SPU or Google’s new Privacy Compute Core; on Linux we harden with TPM 2.0 attestation and dm-verity. This approach dovetails with the EU AI Act and HIPAA’s “minimum necessary” rule, because the data never traverses the WAN. Apple’s Private Cloud Compute has set the bar for hybrid privacy, but clients that need zero telemetry still choose pure on-device builds.
3.4 Lifecycle MLOps & OTA Lite
A traditional OTA drops a 500 MB tarball on every device quarterly; fleets groan, and CFOs see the bandwidth bill. We embed a delta-patching pipeline inspired by bsdiff and Google’s Courgette: only the parameter pages that changed are shipped, often <10 MB. Academic studies in vehicular edge networks confirm that delta packages cut update bandwidth by an order of magnitude while keeping success rates above 99%. A-Bots.com wires this into a Rust micro-service that verifies signatures, applies chunks, and rolls back automatically if a checksum misfires—no more late-night SSH marathons.
3.5 UX, Voice & Multimodal in One SDK
Great latency is wasted if the interface lags. Our front-end engineers ship a shared React Native/Flutter component library so a single codebase targets iOS, Android, and embedded Linux kiosks. For voice we integrate whisper.cpp—a C/C++ port of OpenAI’s Whisper that transcribes speech in real-time on Raspberry Pi 4 or iPhone 13. Need vision? We compile MobileSAM or YOLO-NAS into the same INT4 runtime, letting the assistant “see” and “talk” entirely offline. Customers get multimodal UX without juggling three vendor SDKs.
3.6 Transparent TCO & ROI Modelling
Finally, we put numbers where the hype is. During discovery we run a side-by-side forecast: cloud-API tokens at $0.50/1 K vs. local inference amortised across hardware, storage, and updates. In sectors with 10 k+ daily conversations, breakeven often lands inside six months—even before factoring in regulatory risk. We hand clients a spreadsheet and encourage them to tweak rates; no black-box pricing, just verifiable maths.
If Sections 1 and 2 convinced you that offline AI chat is inevitable, and Section 3 shows how to do it right, book A-Bots.com’s free Offline AI Readiness Audit. You will leave with a model-size budget, compliance gap list, and a delta-update plan—ready to turn “offline AI chat app” from a Google query into a line item on next quarter’s roadmap.
✅ Hashtags
#OfflineAI
#EdgeAI
#OnDeviceLLM
#PrivateChatbot
#AICompliance
#AIChatApp
#ABots
#CustomDev
Other articles
Offline AI Chatbot Development Cloud dependence can expose sensitive data and cripple operations when connectivity fails. Our comprehensive deep-dive shows how offline AI chatbot development brings data sovereignty, instant responses, and 24 / 7 reliability to healthcare, manufacturing, defense, and retail. Learn the technical stack—TensorFlow Lite, ONNX Runtime, Rasa—and see real-world case studies where offline chatbots cut latency, passed strict GDPR/HIPAA audits, and slashed downtime by 40%. Discover why partnering with A-Bots.com as your offline AI chatbot developer turns conversational AI into a secure, autonomous edge solution.
App Development for Elder-Care The world is aging faster than care workforces can grow. This long-read explains why fall-detection wearables, connected pill dispensers, conversational interfaces and social robots are no longer stand-alone gadgets but vital nodes in an integrated elder-safety network. Drawing on market stats, clinical trials and real-world pilots, we show how A-Bots.com stitches these modalities together through a HIPAA-compliant mobile platform that delivers real-time risk scores, family peace of mind and senior-friendly design. Perfect for device makers, healthcare providers and insurers seeking a turnkey path to scalable, human-centric aging-in-place solutions.
Offline-AI IoT Apps by A-Bots.com 2025 marks a pivot from cloud-first to edge-always. With 55 billion connected devices straining backhauls and regulators fining data leaks, companies need AI that thinks on-device. Our long-read dives deep: market drivers, TinyML runtimes, security blueprints, and six live deployments—from mountain coffee roasters to refinery safety hubs. You’ll see why offline inference slashes OPEX, meets GDPR “data-minimization,” and delivers sub-50 ms response times. Finally, A-Bots.com shares its end-to-end method—data strategy, model quantization, Flutter apps, delta OTA—that keeps fleets learning without cloud dependency. Perfect for CTOs, product owners, and innovators plotting their next smart device.
Offline AI Agent for Everyone A-Bots.com is about to unplug AI from the cloud. Our upcoming solar-ready mini-computer runs large language and vision models entirely on device, pairs with any phone over Wi-Fi, and survives on a power bank. Pre-orders open soon—edge intelligence has never been this independent.
Top stories
Copyright © Alpha Systems LTD All rights reserved.
Made with ❤️ by A-BOTS