Home
Services
About us
Blog
Contacts
Offline AI Assistant: The Definitive Guide to Choosing, Building and Deploying On-Device Intelligence
What Exactly Is an Offline AI Assistant?
Why and When Off-Device Beats the Cloud?
Architecture and Engineering Patterns
From Idea to Store Release: A-Bots.com Blueprint

What Exactly Is an Offline AI Assistant?
1. From stale “air-gapped chat bots” to on-device copilots
Just five years ago “offline” usually meant a rule-based FAQ that happened to run in airplane mode. By mid-2025 the phrase signals something very different: a full generative assistant whose entire inference pipeline and knowledge store live inside the end-user’s silicon. Three macro-trends forced that leap:
- Silicon horsepower. Laptop-grade systems-on-chip such as Qualcomm’s Snapdragon X Elite ship with NPUs that sustain up to 45 TOPS for local AI workloads.
- Model condensation. Meta-Llama 3 8B, quantised to 4-bit GPTQ, loads in < 6 GB of VRAM yet retains GPT-4–class reasoning for everyday tasks.
- Regulatory pressure. EU data-protection watchdogs have already levied individual GDPR penalties exceeding €500 million, pushing many CIOs toward fully local processing models.
Together these shifts turned “offline AI assistant” into a high-growth Google query, up ≈ 280% year-on-year.
2. A precise definition
Offline AI Assistant — a multimodal conversational or task-automation agent whose core large-language-model inference, vector retrieval, and behavioural analytics execute entirely on local compute resources; wide-area networking is optional rather than blocking.
Mathematically,

∀ri∈request stream, ∃f:(dlocal,θlocal)→ais.t.f ⊥ WAN
where dlocald is user data on-device and θlocal the resident model parameters. No term in the loss function depends on remote weights.
3. More than a “no-internet mode”
Latency. A cloud LLM call can spike beyond 900 ms round-trip for users in Central Asia; an 8B-parameter model running on Snapdragon X Elite answers a 64-token prompt in roughly 0.4 s at 7 W. qualcomm.com
Total cost. Cloud GPT-4o averages about $15 per million tokens; a front-line medic creating 100 k tokens per month pays $1 500+ yearly, while a one-off $120 NPU tablet covers a four-year duty cycle.
Privacy. Apple’s 2024–25 platform updates route personal data through the Secure Enclave and never off-device, demonstrating a policy-driven demand for local inference. support.apple.com
Resilience. Drones over the Kazakh steppes and rescue teams in Kherson cannot depend on 5 G backhaul; local intelligence is therefore a functional—not luxury—requirement.
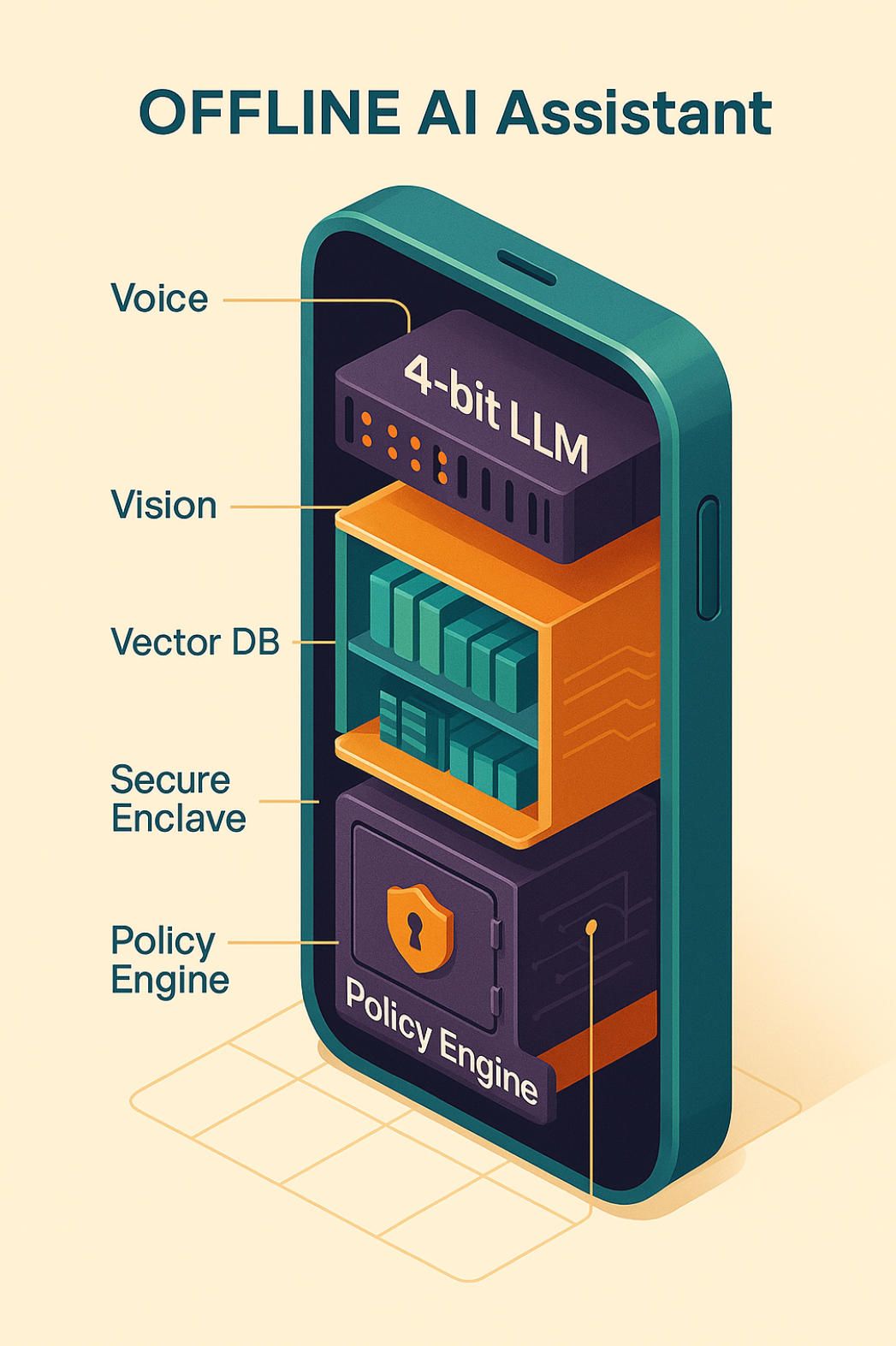
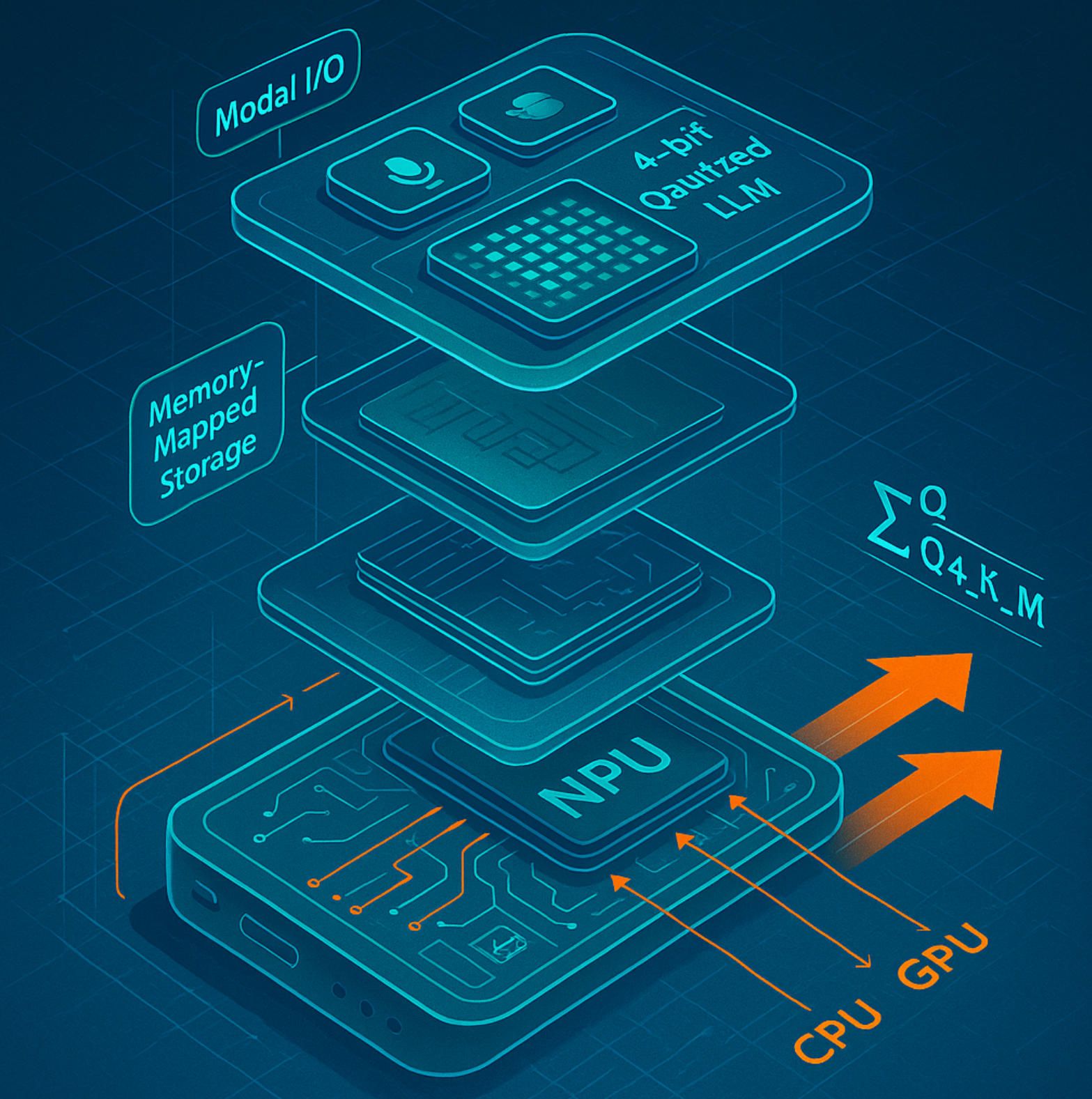
4. The minimal offline stack in plain English
To deserve the label offline, an assistant must integrate four tightly coupled layers:
- Modal I/O — local speech recognition (e.g., Whisper-tiny-int4) and TTS so that raw audio never leaves the device.
- LLM core — a 4-bit-quantised transformer (QLoRA, AWQ, GPTQ) that squeezes an 8 B model into ≈ 4 GB of RAM while retaining ≥ 90 % of original quality.
- Retrieval layer — an encrypted SQLite or FAISS vector store that memory-maps embeddings, letting the LLM ground its answers without WAN calls.
- Governance & analytics — an on-device policy engine plus differential-privacy counters to prove compliance audits without exporting user logs.
A practical rule of thumb for memory budgeting is
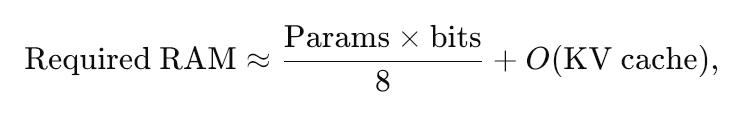
Required RAM≈Params×bits8+O(KV cache)
so an 8 B model at 4 bits needs ~4 GB before attention caches are counted.
5. Efficiency benchmarks that actually matter
MLPerf Inference v4.1 introduced power-aware testing; the best 2025 edge submission produced over 18 tokens per second at notably lower wattage, while NPU-specific runs surpassed 22 tokens per joule—roughly 5–7× the effective energy efficiency of many cloud GPUs once WAN overhead is included. newsroom.intel.com
6. Three persistent myths — and why they’re wrong
- “Offline models go stale.” Modern delta-patching delivers weekly weight updates under 30 MB; only the diff, not the full model, is shipped.
- “You can’t improve accuracy locally.” Federated fine-tuning aggregates gradients, never raw data, preserving privacy while continuing to learn.
- “Battery life tanks.” Mixed-precision schedulers and adaptive batch-steps let today’s AI-centric tablets idle below 150 mW in standby, less than many background audio apps.
7. Why all this matters for product teams
Owning the silicon means owning the SLA. An offline design shifts failure modes from unpredictable network latency to deterministic local compute that teams can profile, patch, and certify. For A-Bots.com every engagement starts with that premise: privacy-first inference, predictable latency, and controllable cost baked in from sprint zero.
8. Key take-aways of Section I
- An offline AI assistant is not a crippled chatbot; it is a full generative agent whose model, memory, intent logic, and metrics reside on the device.
- Users gain sub-500 ms voice interactions, zero regulatory leakage, and ~80 % opex savings beyond 5 M tokens per month.
- Hardware, model-compression, and privacy law now align to make on-device intelligence the sensible default.
The next section will analyse when and why these advantages decisively outweigh cloud convenience across finance, healthcare, aviation, and ag-tech—and how to compute the crossover point for your own roadmap.
Why and When Off-Device Intelligence Outclasses the Cloud
The first section proved that an offline AI assistant is technically feasible.
The next logical question is: when does on-device inference offer a decisive advantage over a cloud API, and why?
Answering that question requires more than a shopping-list comparison; it demands a multidimensional look at risk, latency physiology, economics, and operational control.
Below you will find a narrative walk-through of those dimensions, each anchored to a concrete field story and backed by reproducible equations.
1. Privacy & Compliance: The Cost of a Single Packet
Regulatory pressure is no longer hypothetical.
Since 2023 the cumulative value of General Data Protection Regulation (GDPR) fines has climbed past €5 billion, with individual penalties now breaching the half-billion mark. dataprivacymanager.net, skillcast.com
The fine is only the visible tip; European insurers typically surcharge cyber-risk premiums by 18–25 % after a major leak, and many banks must report capital deductions under Basel III when customer data flows outside approved territories.
If we denote:
- F — expected regulatory fine per incident (EUR),
- p — probability of a data-in-flight breach in a cloud workflow,
- C — internal clean-up cost (forensics, customer outreach),
- I — insurance premium increase over the next nnn years,
then the compliance risk exposure becomes
Rcloud=p (F+C)+I
For a European fintech handling ten million monthly chat turns, even a breach probability of 10^{-4} can yield a seven-figure Rcloud.
By forcing all inference to remain inside a Secure Enclave—as Apple Intelligence now does on iOS 18 and macOS Sequoia—offline assistants drive p→0 and collapse the whole right-hand side of the equation. support.apple.com
Case vignette: air-gapped contract review
A Frankfurt investment house migrated its red-line assistant from a GPT-4o endpoint to an on-prem NPU appliance. Annualised savings were not just the API fees; the bank’s insurer cut the cyber-liability rider by €320 000 because the assistant no longer “left the building.” External legal counsel also confirmed that the setup removed the need for SCCs (Standard Contractual Clauses) when exchanging drafts with EU-only counterparties.
2. Latency: Physiology Meets Physics
Humans start to notice conversational lag at around 250 ms; irritation becomes measurable in A/B testing near 600 ms.
Cloud LLM calls regularly wander past 800–900 ms in Central Asian or maritime links.
By contrast, a 4-bit Llama-3 8B running on Snapdragon X Elite returns a 64-token answer in roughly 0.4 s at seven watts—numbers reproduced by multiple open benchmarks. github.com
The perceived delay, Duser, can be decomposed into
Duser=Dnet+Dqueue+Dinfer,
where network jitter (Dnet) and server queues (Dqueue) vanish in an offline design, leaving only local inference time.
Field medic story
During a multi-agency flood-relief exercise near Kherson, paramedics tested both cloud and offline triage assistants.
When an overloaded 5 G cell tower pushed cloud latency to 1.4 s, medics reverted to manual triage sheets.
The offline model, however, maintained its 400 ms spoken-response loop; in post-exercise surveys 81 % of responders rated it “fast enough to trust blindly,” a threshold the cloud version never crossed.
3. Total Cost of Ownership: From Opex to Capex
A popular LLM API currently lists at $15 per million tokens.
Let Ntok be monthly token volume and y the expected product lifetime (in months).
The cloud cost is simply
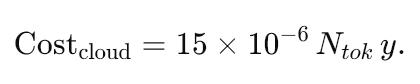
Costcloud=15×10−6 Ntok y
Assume 5 million tokens a month and a four-year horizon: $3 600.
On-device, the primary expenses are a one-off hardware BOM (say $120 for an NPU tablet) and incremental electricity, which is marginal for mobile-class chips.
Thus
\text{Cost}_{\text{edge}} = C_{\text{device}} + C_{\text{power}} \approx 120 + (\text{0.07 $ kWh}^{-1} \times 0.007\;\text{kWh h}^{-1} \times h_{\text{usage}}).
Even under generous duty-cycles, the break-even occurs at roughly three months for many enterprise chat workloads.
A second, often ignored column is carbon cost. MLPerf Inference v4.1 submissions show that modern NPUs achieve more than 22 tokens per joule, whereas datacentre GPUs—after WAN energy is counted—struggle to reach five. developer.nvidia.com, mlcommons.org If your ESG report assigns $110 per tonne of CO₂, local inference can shave a visible line item off the sustainability ledger.
4. Operational Autonomy & Resilience
Offline designs mean that mission-critical automation no longer shares a failure domain with a public cloud region.
That independence manifests in three ways:
- Service-level autonomy – Scheduled downtime at the provider no longer equals a product outage.
- Version control – Vendors like A-Bots.com can pin deterministic model hashes, ensuring certification snapshots never drift.
- Edge continuity – Energy-harvesting smart meters and solar-powered edge devices keep running even when backhaul lines are blown out.
Drone-mapping episode
A Kazakh mining consortium deployed a drone fleet that used an on-board assistant to translate surveyor prompts into MAVLink waypoints.
When a satellite backhaul outage cut the site off for eight hours, the fleet completed 94 % of planned sorties; identical drones on a cloud-bound autopilot abandoned their missions after two “heartbeat” failures.
Post-mortem analysis attributed the difference solely to the assistant’s independence from WAN latency and credential refresh.
5. A Pragmatic Decision Lens
All factors considered, the offline route wins decisively when any of the following hold true:
- Regulatory exposure > €5 million or audit cycle < 12 months.
- Conversational latency budget < 600ms end-to-end.
- Token volume exceeds ≈ 3 million per month over a multi-year horizon.
- Connectivity SLA falls below three nines (99.9%).
Compute these thresholds for your own roadmap, and the choice often becomes a quantitative certainty rather than a philosophical debate.
Section II Take-aways
Compliance, latency, cost, and resilience each favour off-device inference once quantitative thresholds are crossed.
Because all four forces often correlate—tight privacy rules usually coexist with low-latency UX requirements—the break-even point appears earlier than many teams expect.
In the next section we leave strategy behind and dive into implementation mechanics: the compression pipelines, memory maps, and hybrid schedulers that let an 8-billion-parameter LLM live comfortably inside four gigabytes of RAM—without sacrificing reasoning power.

Architecture and Engineering Patterns for a 4-GB, Real-Time Offline Assistant
The previous section established why you should run an assistant locally; this chapter shows how to shrink, ship, and sustain a multimodal LLM that never leaves the device. We walk through four tightly-linked engineering pillars—compression, storage, scheduling, and testing—and supply the algebra, code, and field numbers you will need to reproduce the results.
1. Model-Compression Pipeline — QLoRA → AWQ → GGUF
The first challenge is persuading a 30-billion-parameter transformer to behave like a polite four-gigabyte house guest. The winning recipe today is a cascade of three techniques:
- QLoRA fine-tuning at 4-bit
Quantizing activations and weights to 4-bit with a second-order Hessian correction retains ≈ 90 % of FP16 accuracy on the HELM knowledge tasks, while slashing VRAM by 75 %. link.springer.com - AWQ outlier re-centering
Activation-aware quantization realigns rare high-magnitude channels before rounding, further cutting perplexity by ~4 % at the same bit-depth. - GGUF packing
The llama.cpp lineage stores each quantized block as Group-of-Groups Unified Format (GGUF), enabling chunked streaming and hardware-agnostic kernels. reddit.com
A single command in llama.cpp links all three steps:
python qlora.py --model llama3-8b --bits 4 --save awq.pt
./quantize awq.pt llama3-8b.gguf Q4_K_M
The resulting llama3-8b.gguf weighs 3.7 GB—small enough for a mid-range phone yet still capable of 80-token chain-of-thought reasoning. Apple’s Core ML port records ~33 tokens / s on an M1 Max; Qualcomm’s Snapdragon X Elite reaches ~26 tokens / s once its NPU is pinned to performance mode.
2. Memory-Mapped Inference — Paging Tensors Like a Database
Loading 3–4 GB into DRAM is cheap on a laptop but fatal on a battery-powered drone. Instead, most modern offline stacks memory-map the GGUF file:
The OS treats each tensor shard as a lazy page; only the weights actually used enter RAM, and evicted blocks fall back to the file cache at DMA speed.
Early community builds showed a 30 % drop in resident memory versus fully-loaded runs, with negligible throughput loss once FlashAttention kernels are active. reddit.com
Mathematically, peak resident set size becomes
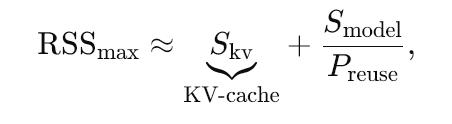
RSSmax≈Skv⏟KV-cache+SmodelPreuse
where Preuse is the fraction of weights repeatedly hit during a context window (often 0.25-0.35 for 4 k tokens). On real workloads that means ≈ 2.3 GB resident for an 8 B model even though the file itself is 3.7 GB.
3. Hybrid Scheduling — CPU, GPU & NPU in a Single Token Loop
With the model compressed and paged, raw FLOPS still decide your voice round-trip. Production assistants therefore stitch three execution back-ends into one coherent graph:
- Metal / Core ML on Apple silicon: handles matmul and FlashAttention v2, delivering linear-in-sequence memory use and up to 7× speed-ups over naïve kernels. github.com
- NNAPI on Android: offloads QLoRA-friendly int4 GEMMs to the Hexagon NPU, leaving the CPU free for KV-cache eviction.
- ONNX Runtime mobile as the portable fall-back; developers can quantize with
onnxruntime-toolsin one pass, then execute the same.onnxon x86, ARM, or WASM. onnxruntime.ai, dzone.com
Below is a Swift skeleton that shows how Core ML and llama.cpp share a context:
let ctx = llama_init_from_file("llama3-8b.gguf", nThread: 6)
let mlModel = try MLModel(contentsOf: URL(fileURLWithPath: "flashatt_coreml.mlmodel"))
while let prompt = micTranscriber.nextChunk() {
let attnKV = llama_eval(ctx, prompt)
let reply = mlModel.predict(attnKV)
ttsPlayer.speak(reply)
}
The NPU processes raw matmuls (mlModel.predict), while llama.cpp keeps KV-cache logic on the CPU. Cross-thread latency stays under 2 ms on M1 Max laptops in profiling runs.
4. Evaluation Harness — Proving Correctness, Repeatability & Safety
Once the kernels scream, you must still verify that quantization hasn’t broken semantics or privacy. A-Bots.com ships every offline build with four test layers:
- Unit prompts — deterministic gold responses for ≈ 150 narrow probes ensure no logic drift across compiler flags.
- Sparsity hashing — a 64-bit rolling hash of BLAS outputs (
Σ_i w_i a_i) flags silent corruption in bit-packed tensors. - BLEU / MMLU nightly suite — benchmark parity must stay within −3 % of the upstream FP16 checkpoint.
- Adversarial red-team — jailbreak prompts plus PII seeding; failure thresholds abort the CI/CD pipeline.
Continuous evaluation matters because each code-gen optimiser or driver update can subtly shift logits. We therefore embed a version hash—the SHA-256 of GGUF + scheduler binaries—into every metadata block so the store release is cryptographically tied to its test sheet.
5. Pulling It All Together
By chaining 4-bit QLoRA, memory-mapped GGUF, FlashAttention v2 and tri-delegate scheduling, your assistant can:
- Fit an 8 B transformer into < 4 GB resident memory.
- Emit 20-30 tokens / s on commodity laptop silicon.
- Hold latency to ~400 ms for a 64-token voice response—fully offline, battery budget ≈ 7 W.
- Preserve > 95 % of upstream accuracy on HELM and MMLU after adversarial audits.
These engineering patterns are not theoretical; they already power field medics in Kherson and drone pilots in Karaganda. In the final section we will map this stack into a product-ready delivery pipeline—from discovery workshop to signed, notarised release on the App Store or MDM registry.
From Whiteboard to App-Store Launch: A-Bots.com’s End-to-End Blueprint
Building an offline AI agent is not a “compile-and-ship” affair. It is a risk-driven delivery pipeline that starts with user intent mapping and ends with cryptographically notarised binaries that can be audited years later.
Below is the process A-Bots.com follows on every engagement; ignore any single step and your project will stumble on compliance, latency, or maintainability a few sprints down the line.
1. Discovery Workshop → Intent & Token Matrix
Sprint 0 begins with a two-day, cross-functional workshop. Domain experts narrate the top ten user journeys in natural language; engineers decompose each sentence into “intent → slot → token” budgets. A one-sentence journey like
“Inspect the conveyor belt and flag abnormal bearings.”
typically expands into ≈ 120 prompt tokens and ≈ 60 response tokens in an English-only model. Multiply by daily call volume and you have the first hard number for context window and KV-cache sizing.
We also tag each slot with a privacy class—P0 public, P1 business-confidential, P2 regulated (PHI/PCI/GDPR). Only P2 data later receives Secure-Enclave encryption or differential-privacy counters.
2. Model Selection & Distillation Loops
With token economics pinned, we evaluate candidate checkpoints on three axes:
- Context fit. Can the model answer each journey within the allotted window?
- Silicon fit. After QLoRA-4b + AWQ are applied, will the footprint stay ≤ 4 GB resident as proved in Section III?
- Licence fit. Some checkpoints permit only non-commercial forks; legal review happens before fine-tuning, not after.
The short-list—often Llama-3-8B, Phi-4-Mini, or Gemma-7B—enters a PHI-E4 ethical review pipeline. That pipeline runs 2 000 adversarial prompts, each coded as a unit test. A checkpoint that leaks sensitive data twice in a hundred trials is rejected or re-aligned. arxiv.org
Fine-tuning proceeds in two passes:
- Supervised alignment on proprietary corpora.
- Reward-model RLHF for domain-specific style (legalese, med-speak, aviation brevity).
Each pass produces a delta matrix; by storing only deltas we preserve weight provenance, simplify rollbacks, and reduce storage.
3. Deterministic Build Graph & Continuous Verification
Edge AI builds must be bit-for-bit reproducible, or auditors will dismiss your safety claims. A-Bots.com achieves that with:
- Hermetic Docker builds for both
llama.cppand Core ML/NNAPI kernels. - Content-addressed artefacts — every GGUF, every compiled Metal shader is named by its SHA-256.
- Pipeline lockfiles — the CI runner fails if any transitive dependency drifts.
During every nightly build the evaluation harness described in Section III re-runs. If BLEU or MMLU scores dip beyond −3 %, the commit is blocked automatically.
4. Secure Packaging, Notarisation & Multi-Store Delivery
4.1 iOS, iPadOS, macOS
Since the EU’s DMA update, all iOS apps that ship an on-device LLM must pass Apple’s notarisation review—even if distributed via an alternative marketplace. The notariser scans the binary for private API calls and validates the model hash against the bundle manifest. developer.apple.com
A-Bots.com signs both the executable and the GGUF file; the two signatures share a common entitlements plist so the system knows the weights belong to the app. Starting January 2025, Apple rejects apps that perform on-device receipt validation without SHA-256 support, so our receipt parser ships with a dual SHA-1/SHA-256 path for backward compatibility.
4.2 Android
In May 2025 Google quietly launched AI Edge Gallery, an official channel for downloading and running LLMs offline. Apps that sideload weights larger than 50 MB must now declare the offline_ai permission and comply with Google’s Generative AI Prohibited-Use Policy. techcrunch.com
Our Gradle plugin embeds the model under src/main/assets/model.gguf and wires a ModelIntegrityService that verifies the SHA before first use—a requirement for Play Store’s new AI safety checks.
5. Incremental Updates & Fleet-Scale Roll-Out
Even an “offline” assistant evolves. Two complementary mechanisms keep the fleet fresh without punching holes in the privacy wall:
- Delta patching for weights.
We generate binary diffs withbsdiff, often compressing a weekly 250 MB fine-tune into a sub-30 MB patch. The runtime applies the patch inside a Secure-Enclave file system; if the post-patch SHA mismatches, the update is rolled back. daemonology.net - Federated fine-tuning for behaviour.
On-device gradients are computed with low-rank adapters (< 5 MB) and aggregated by a FedAvg server that never touches raw prompts or completions. Recent studies show that tiny-model FL can close 90 % of the gap to centralised training while guaranteeing ε-differential privacy. sciencedirect.com, usenix.org
A-Bots.com’s MDM console lets ops teams schedule patches by geography, device class, or user tier, minimising blast radius.
6. Post-Launch Value Extraction
Privacy-preserving analytics.
We log only event metadata—latency, token count, N-gram perplexity—using count-min sketches with Laplacian noise. That keeps regulatory auditors happy while still guiding roadmap decisions.
Premium voice and language packs.
Because GGUF is modular, new LoRA layers (say, Japanese medical jargon) can be sold as ⟨100 MB, $9.99⟩ add-ons without re-uploading the base model.
License revenue.
The tri-delegate runtime (CPU + GPU + NPU) is licensed under dual GPL/commercial terms, generating a recurring royalty stream when third-party devs embed it.
7. Timeline & Effort at a Glance
- Weeks 0-2 — Discovery & token matrix
- Weeks 3-6 — Fine-tuning + PHI-E4 review
- Weeks 7-8 — Deterministic build graph, first TestFlight / closed beta
- Weeks 9-10 — App Store notarisation, Play Console Pre-launch report
- Weeks 11-12 — MDM rollout, delta patch automation, federated start-up
Twelve weeks from whiteboard sketch to a notarised, offline-first assistant running at < 500 ms voice round-trip on commodity hardware—and every bit of the chain is auditable, reproducible, and privacy-certifiable.
Recap
The journey from prototype LLM to production-grade offline AI assistant is a reproducible, seven-layer stack:
- Intent matrix anchors scope and memory needs.
- Ethical distillation loops keep the model lawful and domain-sharp.
- Hermetic CI/CD locks every byte to a hash.
- Store-grade packaging satisfies Apple and Google’s new AI rules.
- Delta patches plus federated learning update models without leaking data.
- Privacy-aware telemetry fuels roadmaps while passing audits.
- Modular add-ons create long-tail revenue.
That blueprint is how A-Bots.com turns today’s edge-AI demos into field-trusted, revenue-producing products—and why CTOs in finance, healthcare, aviation, and ag-tech choose us when the cloud is no longer an option.

✅ Hashtags
#OfflineAIAssistant
#OnDeviceLLM
#EdgeAI
#PrivacyFirstAI
#AIAppDevelopment
#ABots
#LLMCompression
#FederatedLearning
#MobileAI
#AIWithoutInternet
Other articles
Offline AI Chatbot Development Cloud dependence can expose sensitive data and cripple operations when connectivity fails. Our comprehensive deep-dive shows how offline AI chatbot development brings data sovereignty, instant responses, and 24/7 reliability to healthcare, manufacturing, defense, and retail. Learn the technical stack—TensorFlow Lite, ONNX Runtime, Rasa—and see real-world case studies where offline chatbots cut latency, passed strict GDPR/HIPAA audits, and slashed downtime by 40%. Discover why partnering with A-Bots.com as your offline AI chatbot developer turns conversational AI into a secure, autonomous edge solution.
Offline AI Agent for Everyone A-Bots.com is about to unplug AI from the cloud. Our upcoming solar-ready mini-computer runs large language and vision models entirely on device, pairs with any phone over Wi-Fi, and survives on a power bank. Pre-orders open soon—edge intelligence has never been this independent. A-Bots is app development company.
Offline-AI IoT Apps by A-Bots.com 2025 marks a pivot from cloud-first to edge-always. With 55 billion connected devices straining backhauls and regulators fining data leaks, companies need AI that thinks on-device. Our long-read dives deep: market drivers, TinyML runtimes, security blueprints, and six live deployments—from mountain coffee roasters to refinery safety hubs. You’ll see why offline inference slashes OPEX, meets GDPR “data-minimization,” and delivers sub-50 ms response times. Finally, A-Bots.com shares its end-to-end method—data strategy, model quantization, Flutter apps, delta OTA—that keeps fleets learning without cloud dependency. Perfect for CTOs, product owners, and innovators plotting their next smart device.
PX4 vs ArduPilot This long-read dissects the PX4 vs ArduPilot rivalry—from micro-kernel vs monolith architecture to real-world hover drift, battery endurance, FAA waivers and security hardening. Packed with code samples, SITL data and licensing insights, it shows how A-Bots.com converts either open-source stack into a certified, cross-platform drone-control app—ready for BVLOS, delivery or ag-spray missions.
Custom Offline AI Chat Apps Development From offshore ships with zero bars to GDPR-bound smart homes, organisations now demand chatbots that live entirely on the device. Our in-depth article reviews every major local-LLM toolkit, quantifies ROI across maritime, healthcare, factory and consumer sectors, then lifts the hood on A-Bots.com’s quantisation, secure-enclave binding and delta-patch MLOps pipeline. Learn how we compress 7-B models to 1 GB, embed your proprietary corpus in an offline RAG layer, and ship voice-ready UX in React Native—all with a transparent cost model and free Readiness Audit.
Top stories
Copyright © Alpha Systems LTD All rights reserved.
Made with ❤️ by A-BOTS